Bojie Li (李博杰)
2024-04-15
(本文首发于知乎回答:《如何培养在计算机系统领域的研究品味(Research Taste)?》)
转眼间从科大本科毕业已经接近 10 年了。昨天跟老婆讨论我们科大系统圈子同学近期的发展,就发现 research taste 是决定学术成果最关键的因素。第二关键的因素则是动手能力。
什么是 research taste?我认为,research taste 就是找到未来有影响力的研究方向和研究课题。
很多同学技术很强,也就是动手能力很强,系统实现能力很强,但是仍然做不出来有影响力的研究成果,主要原因就是 research taste 比较差,选的研究方向要么只是蹭热点,缺少自己的思考;要么过于小众,没有人关注。
博士生的 research taste 靠导师
我认为,research taste 早期主要靠导师培养,后续主要靠自己的愿景。
2024-04-14
(本文首发于知乎回答:《目前大语言模型的评测基准有哪些?》)
必须吹一波我们 co-founder @SIY.Z 的 Chatbot Arena 呀!
Chatbot Arena 是基于社区评价的大模型评测基准。上线一年来,Chatbot Arena 已经有超过 65 万次有效用户投票。
Chatbot Arena 见证大模型的快速进化
最近的一个月,我们在 Chatbot Arena 上见证了几件非常有趣的事情:
- Anthropic 的 Claude-3 发布,大杯 Opus 模型的性能超越了 GPT-4-Turbo,中杯 Sonnet 和小杯 Haiku 模型的性能也追平了 GPT-4。这是 OpenAI 以外的公司首次夺得排行榜的首位。Anthropic 的估值已经 $20B,直逼 OpenAI 的 $80B 了,OpenAI 是应该有点危机感了。
- Cohere 发布了迄今最强的开源模型 Command R+,104B 模型的性能追平 GPT-4,当然跟 GPT-4-Turbo 还有一定差距。我今年年初接受甲子光年采访的时候提出了 2024 年大模型四大趋势(《AI 一天,人间一年:我与 AI 的 2023|甲子光年》):“多模态大模型能够实时理解视频,实时生成包含复杂语义的视频;开源大模型达到 GPT-4 水平;GPT-3.5 水平开源模型的推理成本降到 GPT-3.5 API 的百分之一,让应用在集成大模型的时候不用担心成本问题;高端手机支持本地大模型和自动 App 操控,每个人的生活都离不开大模型。” 第一个是 Sora,第二个是 Command R+,都已经应验。我还是重复这个观点,如果一家主要做基础模型的公司 2024 年还训练不出 GPT-4 的话,就不用再折腾了,浪费了大量算力,最后连开源模型都比不上。
- 通义千问发布了 32B 开源模型,几乎可以达到 top 10,不管中文英文都很能打。32B 模型在成本上的杀伤力还是很强的。
- OpenAI 被 Anthropic 的 Claude Opus 超过了,自然也不示弱,马上发布了 GPT-4-Turbo-2024-04-09,又夺回了排行榜上第一的宝座。不过 OpenAI 迟迟没有发布 GPT-4.5 或者 GPT-5,而且大家期待的多模态模型一直没有出来,这是有点令人失望的。
2024-04-07
本视频是 B 站 Up 主 “苹果冒个泡儿” 对我的采访视频,原视频链接
整个采访半个小时,是一次录完的,除了 Up 主加的片头之外,基本上没有剪辑,也没有提前准备问题的回答。
(27:07,136 MB)
2024-03-29
(全文约 4 万字,主要内容来自 2023 年 12 月 21 日在中科大校友会 AI 沙龙上的 2 小时报告,也是 2024 年 1 月 6 日知乎 AI 先行者沙龙 15 分钟报告内容的技术扩展版本,文章经笔者整理和扩展)

非常荣幸来到科大校友会 AI 沙龙分享一些我对 AI Agent 的思考。我是 1000(2010 级理科实验班)的李博杰,2014-2019 年在中科大和微软亚洲研究院读联合培养博士,2019-2023 年是华为首届天才少年,如今我跟一批科大校友一起在做 AI Agent 领域的创业。
今天是汤晓鸥教授的头七,因此我特别把今天的 PPT 调成了黑色背景,这也是我第一次用黑色背景的 PPT 做报告。我也希望随着 AI 技术的发展,未来每个人都可以有自己的数字分身,实现灵魂在数字世界中的永生,在这个世界里生命不再有限,也就不再有分离的悲伤。
AI:有趣和有用
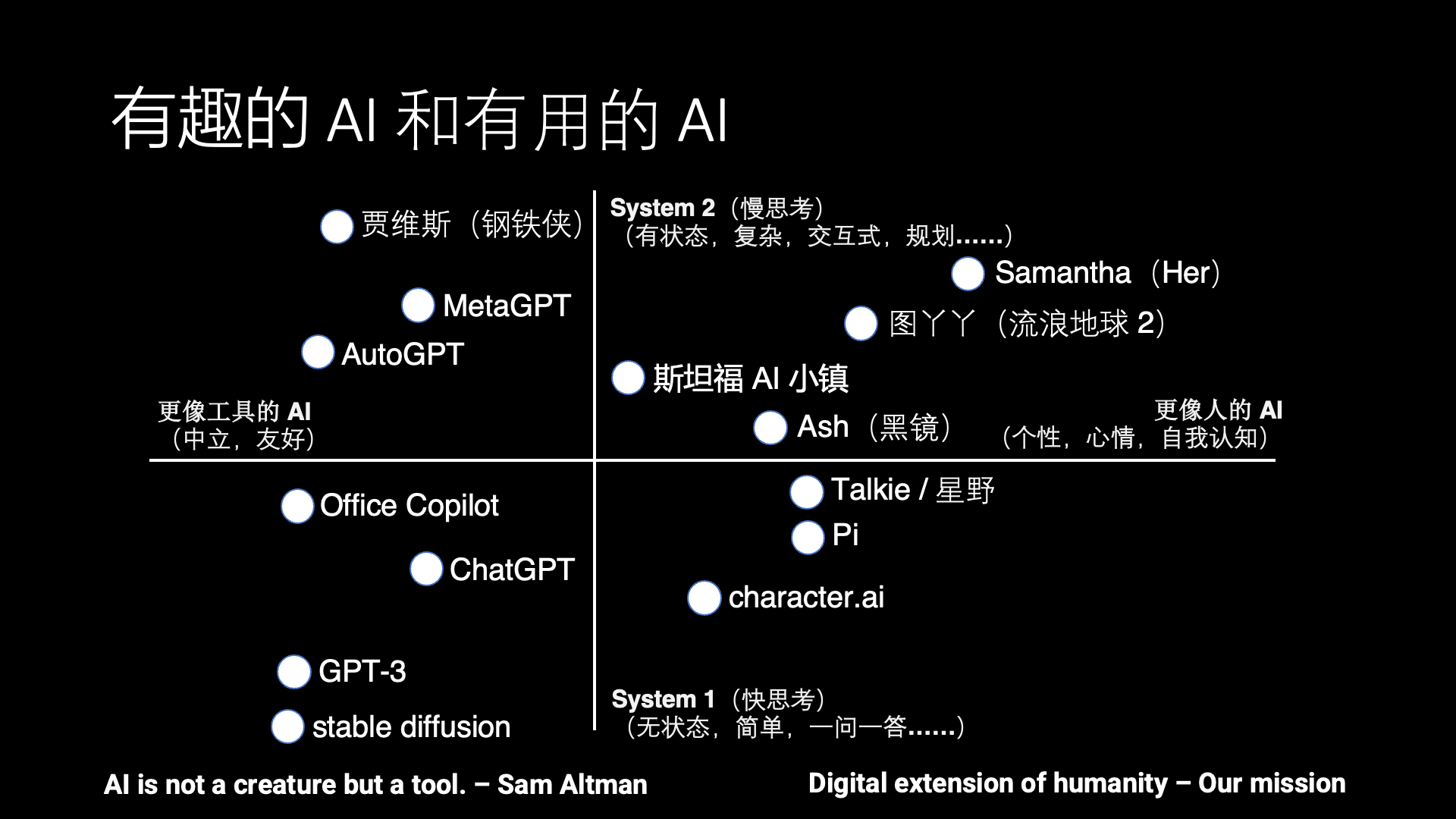
AI 的发展目前一直有两个方向,一个是有趣的 AI,也就是更像人的 AI,另外一个方向就是更有用的 AI,也就是更像工具的 AI。
AI 应该更像人还是更像工具呢?其实是有很多争议的。比如说 OpenAI 的 CEO Sam Altman 就说,AI 应该是一个工具,它不应该是一个生命。而很多科幻电影里的 AI 其实更像人,比如说 Her 里面的 Samantha,还有《流浪地球 2》里面的图丫丫,黑镜里面的 Ash,所以我们希望能把这些科幻中的场景带到现实。只有少数科幻电影里面的 AI 是工具向的,比如《钢铁侠》里面的贾维斯。
除了有趣和有用这个水平方向的之外,还有另外一个上下的维度,就是快思考和慢思考。这是一个神经科学的概念,出自一本书《思考,快与慢》,它里面就说人的思考可以分为快思考和慢思考。
所谓的快思考就是不需要过脑子的基础视觉、听觉等感知能力和说话等表达能力,像 ChatGPT、stable diffusion 这种一问一答、解决特定问题的 AI 可以认为是一种工具向的快思考,你不问它问题的时候,它不会主动去找你。而 Character AI、Inflection Pi 和 Talkie(星野)这些 AI Agent 产品都是模拟一个人或者动漫游戏角色的对话,但这些对话不涉及复杂任务的解决,也没有长期记忆,因此只能用来闲聊,没法像 Her 里面的 Samantha 那样帮忙解决生活和工作中的问题。
而慢思考就是有状态的复杂思考,也就是说如何去规划和解决一个复杂的问题,先做什么、后做什么。比如 MetaGPT 写代码是模拟一个软件开发团队的分工合作,AutoGPT 是把一个复杂任务拆分成很多个阶段来一步步完成,虽然这些系统在实用中还有很多问题,但已经是一个具备慢思考能力的雏形了。
遗憾的是,现有产品中几乎没有在第一象限,兼具慢思考和类人属性的 AI Agent。斯坦福 AI 小镇是个不错的学术界尝试,但斯坦福 AI 小镇里面没有真人的交互,而且 AI Agent 一天的作息时间表都是事先排好的,因此并不是很有趣。
有趣的是,科幻电影里面的 AI 其实大部分是在这个第一象限。因此这就是目前 AI Agent 和人类梦想之间的差距。因此我们在做的事情跟 Sam Altman 说的正好相反,我们希望让 AI 更像人,同时又具备慢思考的能力,最终演进成一个数字生命。
2024-02-25
从 2023 年 12 月开始,我作为企业导师,跟国科大刘俊明教授合作了一个 AI Agent 实践课题,有大约 80 名来自全国各地的学生参加,大部分是只会基本编程的本科生,也有一部分有 AI 基础的博士生和硕士生。
2023 年 12 月和 2024 年 1 月开了 6 次组会,讲解了 AI Agent 的基础知识、OpenAI API 的用法、本次 AI Agent 实践课题,并解答同学们在实践过程中遇到的问题。实践课题包括:
- 企业 ERP 助手
- 狼人杀
- 智能数据采集
- 手机语音助手
- 会议助手
- 老友重逢
- 谁是卧底
2 月 20-24 日,参与这个研究课题的部分同学集中在北京进行 Hackathon,并展示了项目的阶段成果。参与的同学普遍感受到大模型能力的强大,没想到这么复杂的功能仅用几百行代码就做出来了。以下是部分展示的项目成果:
2024-02-22
最近 Groq 推理芯片以 500 token/s 的大模型输出速度刷屏了。
一句话来说,这个芯片就是玩了个用空间换时间的把戏,把模型权重和中间数据都放在了 SRAM 里面,而不是 HBM 或者 DRAM。
这是我 8 年前在微软亚洲研究院(MSRA)就做过的事情,适用于当时的神经网络,但真的不适合现在的大模型。因为基于 Transformer 的大模型需要很多内存用来存储 KV Cache。
Groq 芯片虽然输出速度非常快,但由于内存大小有限,batch size 就没法很大,要是算起 $/token 的性价比来,未必有竞争力。
Groq 需要几百卡的集群才能跑 LLaMA-2 70B 模型
2024-02-20
我与 AI 的早期接触
读博期间与 AI 的邂逅
我博士本来是做网络和系统研究的,博士论文就是《基于可编程网卡的高性能数据中心系统》。很多做网络和系统的人看不起一些 AI 研究,说 AI 的文章容易灌水,只要有 idea,一两个月就可以发出 paper 来。而网络和系统的顶会文章往往需要很大的工作量,做一年之久。
除了在学校的时候上过的那些 AI 的课,我第一次正经做 AI 相关的项目是 2016 年,用 FPGA 加速 Bing Ranking 里面的神经网络。当时正好是 AI 的上一波热潮,今天的 AI 四小龙都是那段时间启动的。
微软把 FPGA 大规模部署到数据中心,除了网络虚拟化,还有很重要的一块就是神经网络推理加速。当时我们还用流水线并行来把神经网络的权重全部放到 FPGA 片上的 SRAM 里面,从而实现超线性的加速比。这段故事在《MSRA 读博五年——自己主导的第一篇 SOSP》中 “机器学习加速器的探索” 一节有更详细的描述。
当时搞网络和系统的很多人对 AI 并不了解,也不屑于了解,连训练和推理都分不清,也搞不清正向和反向算子。通过优化这些算子,我至少知道了基本的前馈神经网络(FFNN)到底是怎么算的。但我并没有接触业务,没有折腾过自己的模型。
2024-02-16
投资人圈子里今天流传一个段子:今天终于可以睡个好觉了,因为再也不用担心哪天我投资的那些视频生成公司被别人超过了。
上个月接受甲子光年采访《AI 一天,人间一年:我与 AI 的 2023|甲子光年》的时候,我预测了 2024 年的四大趋势,第一条就是视频生成,没想到这么快就成真了。(当然,目前 Sora 生成的视频包含的语义还并不复杂,而且也做不到实时生成,所以大家还有机会)
- 多模态大模型能够实时理解视频,实时生成包含复杂语义的视频;
- 开源大模型达到GPT-4 水平;
- GPT-3.5 水平开源模型的推理成本降到 GPT-3.5 API 的百分之一,让应用在集成大模型的时候不用担心成本问题;
- 高端手机支持本地大模型和自动 App 操控,每个人的生活都离不开大模型。
视频生成模型是世界模拟器
OpenAI 的技术报告标题也很有深意:视频生成模型是世界模拟器。(Video generation models as world simulators)
技术报告的最后一句话我觉得写得也很好:我们相信,Sora 如今所展现出的能力表明,持续扩展视频模型是一条通往强大模拟器的希望之路,可以模拟物理世界、数字世界以及生活在这些世界中的对象、动物和人。
其实 OpenAI 早在 2016 年,就明确提出生成模型是让计算机理解世界最有潜力的方向。还专门引用了物理学家费曼的一句话:What I cannot create, I do not understand. (我不能创作出来的,我就没有理解)
2024-02-14
导师推荐我读 Peter Thiel 的 Zero to One,真的是创业必读。Peter Thiel 是硅谷的天使,投资界的思想家,PayPal 黑帮创始人。
所以《黑天鹅》的作者对这本书的评价是,当一个有冒险精神的人写书了,务必要读一读。如果作者是 Peter Thiel,就要读两遍。但是保险起见,请读三遍,因为《Zero to One》绝对是经典之作。
读完这本书最大的感受是,创业和做研究在很多方面上几乎是一样的。
所有赚钱的公司都是垄断公司
书中最有趣的观点就是,所有成功的企业都是不同的,或者说所有赚钱的公司都是垄断公司。
书中讨论的垄断公司并不是借助政府资源实现垄断,而是通过创新,使它供给消费者的产品其他企业无法供给。
如果一个行业里存在多家完全竞争的公司,不管创造多少价值,公司的盈利都不会太多。例如美国航空业每年创造数千亿美元的价值,但每次飞行航空公司只能从每位乘客身上赚到 37 美分。Google 每年创造的价值不如航空业多,但利润是 21%,利润率是航空业的 100 多倍。
垄断者为了自我保护会撒谎,通过把自己的市场定位成多个大市场的并集来虚构并不存在的竞争。例如 Google 没有把自己定位成一家搜索引擎公司,而是定位成一家广告公司或者多元科技公司,后两者的市场更大,Google 只是整个市场中不起眼的小卒。
而非垄断者为了夸大自己的独特性,往往把自己的市场定义成各种更小市场的交集。例如 Palo Alto 的英式餐厅,或者唯一一家开发电子邮件支付系统的公司(PayPal)。
但把市场描述得太狭小是一种致命的诱惑,表面上看起来能够理所当然地驾驭它,但这样的市场可能根本不存在,或者太小了,支撑不起一家公司来。
2024-02-07
(本文转载自 甲子光年公众号,感谢甲子光年的采访)

总结 2023,启程 2024。
作者|刘杨楠 苏霍伊 赵健
最近一两周,很多公司都在紧锣密鼓地开战略会,明确 2024 年的目标与规划。
经过一年多 AI 狂飙带来的推背感,是时候给忙碌的 2023 年做一个年终总结了。开完战略会、进入春节假期,大部分公司才会真正停下步履不停的脚步,进入短暂而难得的休息状态。
那么,如何总结 2023 年呢?
「甲子光年」邀请了基础大模型、AI Infra(AI 基础设施)、多模态、行业垂直场景与学术研究等领域的 30 多位 AI 从业者,分别抛出了 5 个问题:
2023 年你的关键词是什么?
2023 年你所经历的 Magic Moment(印象最深刻的一个瞬间)是什么时候?
2023 年你是否在一轮又一轮的技术冲击中彷徨过?从彷徨到豁然开朗,中间的转折点是什么?
预测一下 2024 年 AI 行业可能发生的重要事件?
如果对一年前的自己说一句话,你会说什么?如果向一年后的自己问一个问题,你会问什么?
他们的彷徨与焦虑、激动与兴奋,是 AI 行业一整年的缩影;他们的探索与坚持、刷新与迭代,将是未来五年甚至十年 AI 大爆炸的前奏。
以下是他们的分享(按姓名首字母排序)。