Chatbot Arena: A Community-Based Evaluation Benchmark for Large Models
(This article was first published on Zhihu Answer: “What are the current benchmarks for evaluating large language models?”)
We must praise our co-founder @SIY.Z for Chatbot Arena!
Chatbot Arena is a community-based evaluation benchmark for large models. Since its launch a year ago, Chatbot Arena has received over 650,000 valid user votes.
Chatbot Arena Witnesses the Rapid Evolution of Large Models
In the past month, we have witnessed several very interesting events on Chatbot Arena:
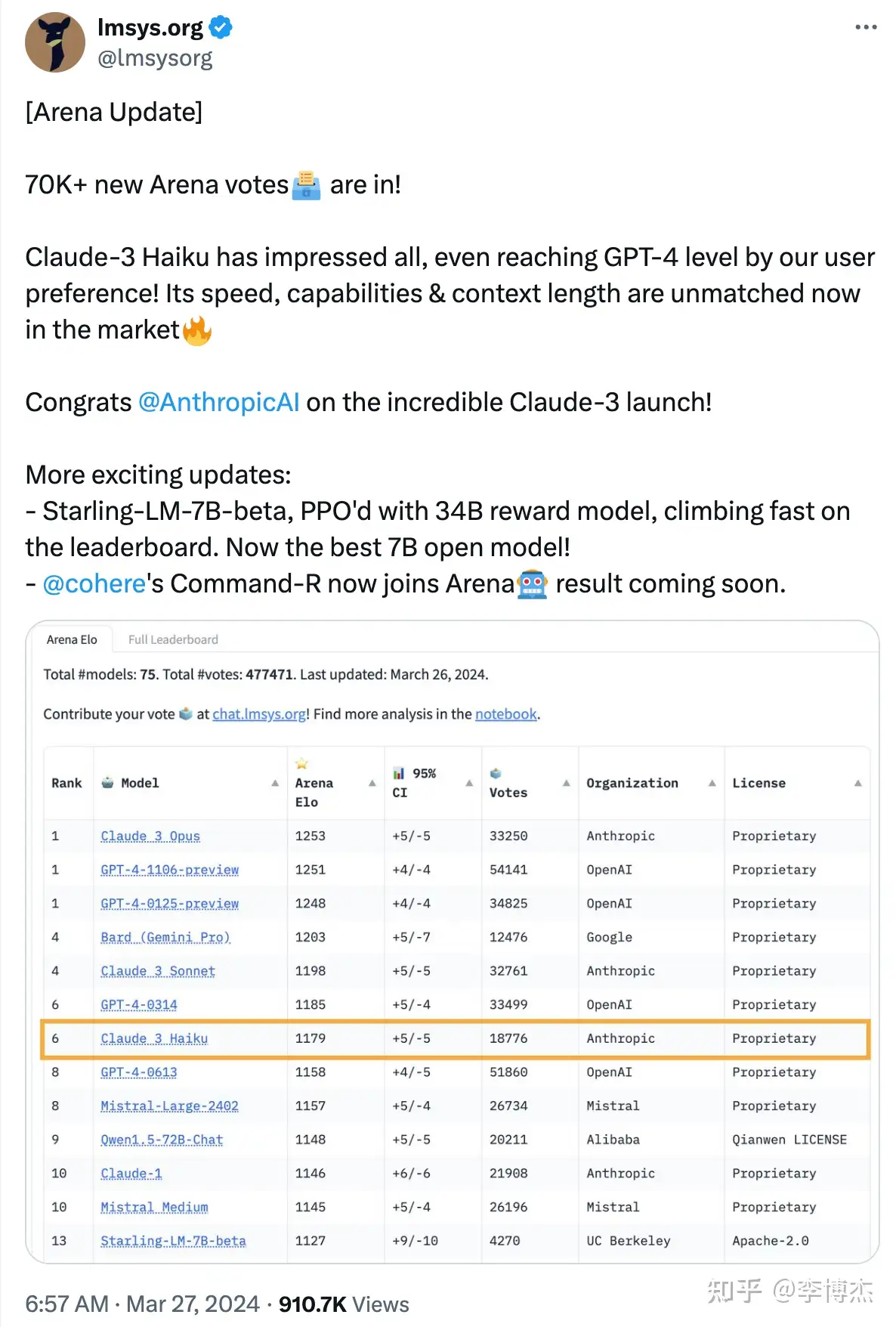
- Anthropic’s release of Claude-3, with its large Opus model surpassing GPT-4-Turbo, and its medium Sonnet and small Haiku models matching the performance of GPT-4. This marks the first time a company other than OpenAI has taken the top spot on the leaderboard. Anthropic’s valuation has reached $20B, closely approaching OpenAI’s $80B. OpenAI should feel a bit threatened.
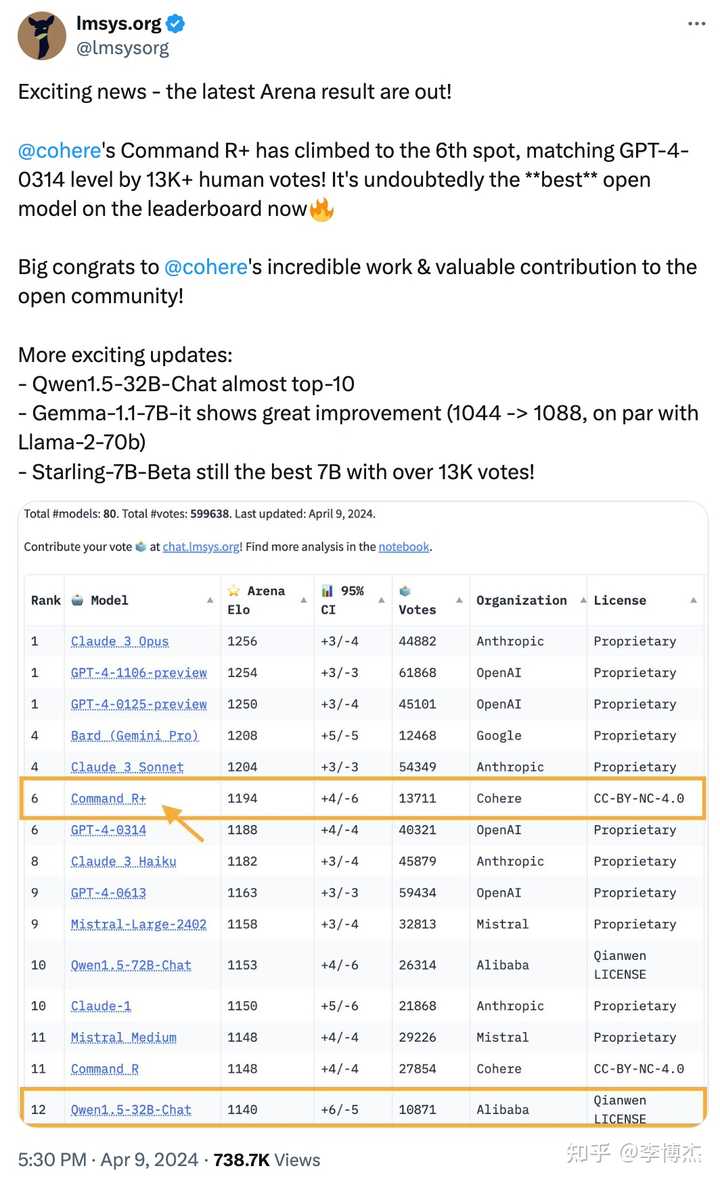
- Cohere released the strongest open-source model to date, Command R+, with a 104B model matching the performance of GPT-4, although still behind GPT-4-Turbo. Earlier this year, I mentioned the four major trends for large models in 2024 during an interview with Jiazi Guangnian (“AI One Day, Human One Year: My Year with AI | Jiazi Guangnian”): “Multimodal large models capable of real-time video understanding and generating videos with complex semantics; open-source large models reaching GPT-4 level; the inference cost of GPT-3.5 level open-source models dropping to one percent of the GPT-3.5 API, making it cost-effective to integrate large models; high-end smartphones supporting local large models and automatic app operation, making everyone’s life dependent on large models.” The first is Sora, the second is Command R+, both have come true. I still hold this view, if a company mainly focused on foundational models cannot train a GPT-4 by 2024, they should stop trying, wasting a lot of computing power, and not even matching open-source models.
- Tongyi Qianwen released a 32B open-source model, almost reaching the top 10, performing well in both Chinese and English. The cost-effectiveness of the 32B model is still very strong.
- OpenAI was surpassed by Anthropic’s Claude Opus, and naturally, they did not show weakness, immediately releasing GPT-4-Turbo-2024-04-09, reclaiming the top spot on the leaderboard. However, OpenAI has been slow to release GPT-4.5 or GPT-5, and the much-anticipated multimodal model has not yet appeared, which is somewhat disappointing.
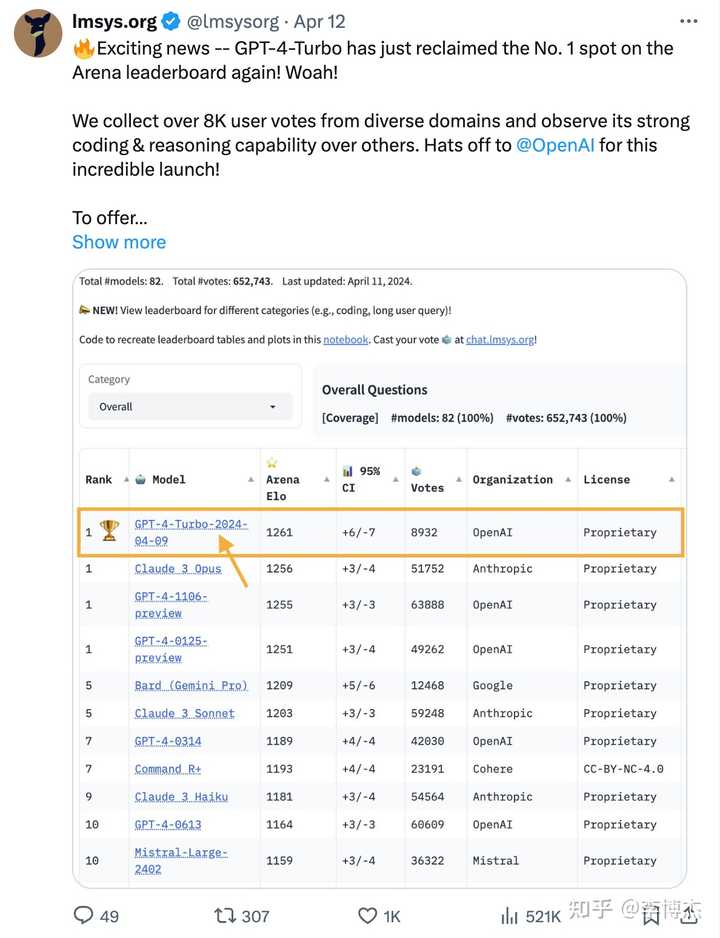
The Authority of Chatbot Arena
So, how authoritative is this Chatbot Arena, and is it just for fun? OpenAI and Google have both retweeted Chatbot Arena’s Twitter to corroborate their large models’ performance. Domestic companies rarely cite Chatbot Arena’s evaluation results, mainly due to compliance reasons, fearing that user-generated content on overseas platforms is uncontrollable.
OpenAI’s chairman and co-founder Greg Brockman’s last Twitter post before being fired on November 18 last year was a retweet of Chatbot Arena, at that time GPT-4-Turbo had just surpassed GPT-4 to become the top of the leaderboard. About ten minutes after posting this tweet, he was fired by the board. Consequently, many people asked LMSys (UC Berkeley’s academic organization behind Chatbot Arena) what their relationship was with OpenAI’s palace intrigue. It was just a coincidence, completely unrelated.
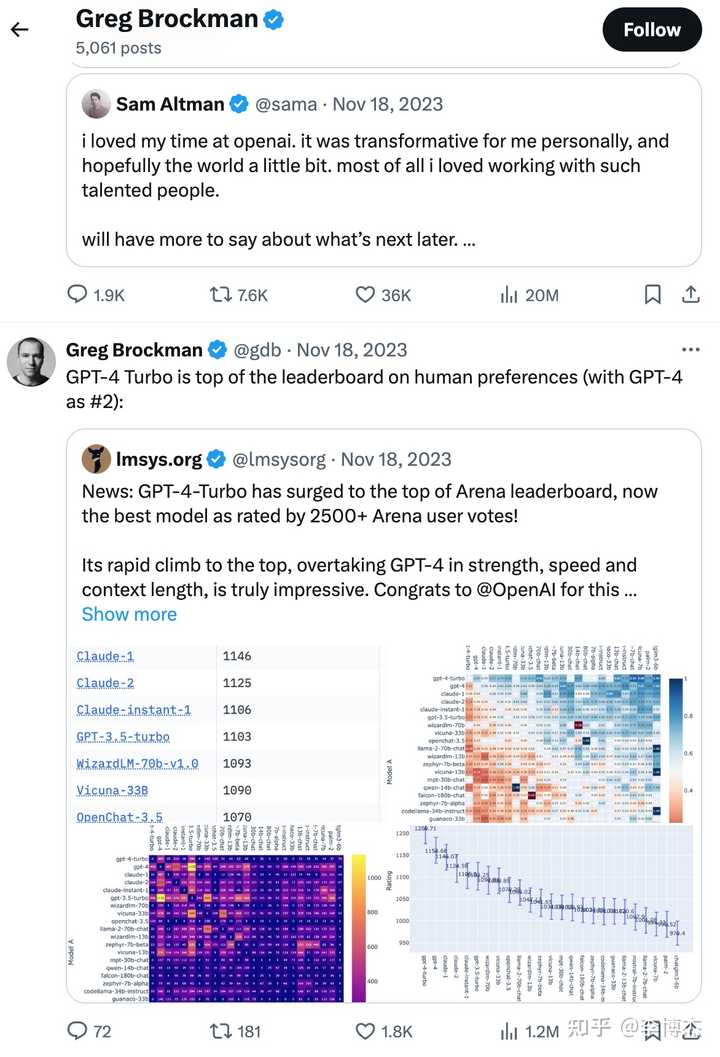
Google’s Jeff Dean also cited Chatbot Arena’s leaderboard when releasing Gemini Pro.
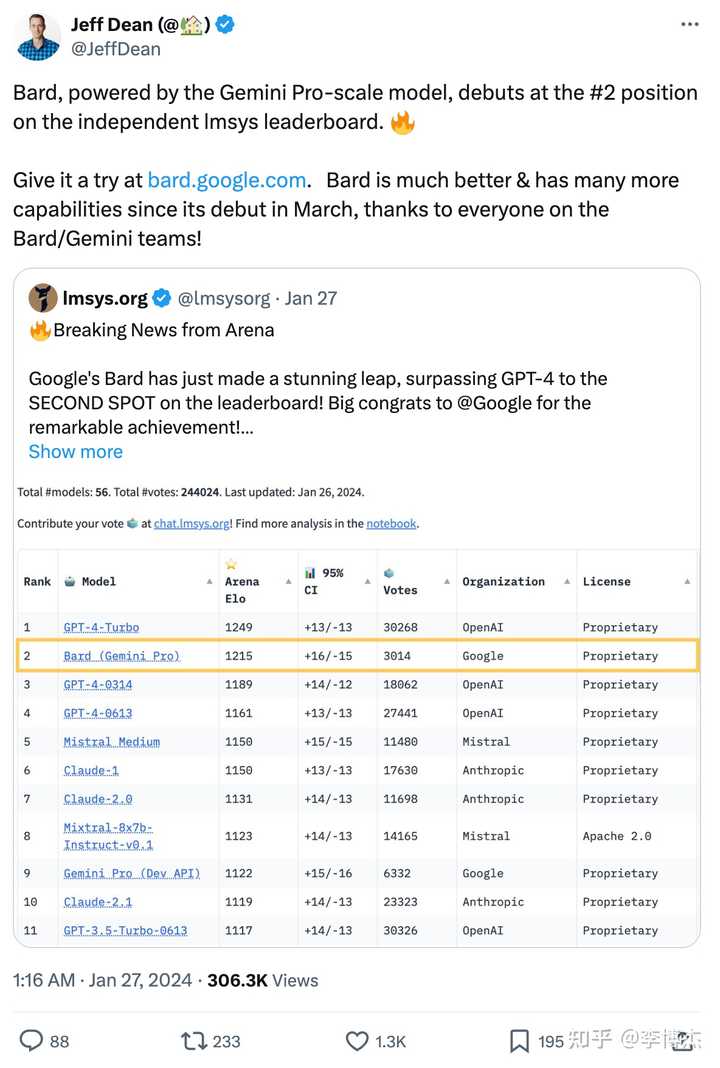
Google CEO also followed LMSys’s Twitter.
OpenAI founding team member Andrej Karpathy even said last year that they only trust two large model evaluation benchmarks: Chatbot Arena and r/LocalLlama.
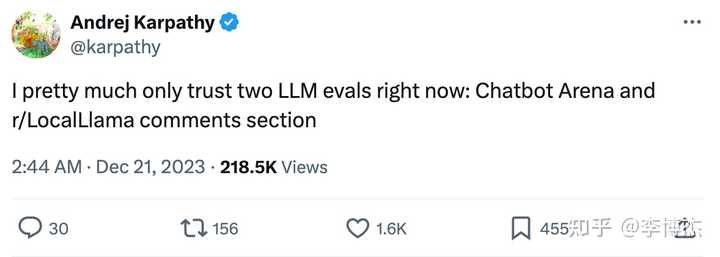
Both of these large model evaluation benchmarks use community evaluation methods, allowing anonymous users in the community to evaluate the outputs of large models.
The Issue of Dataset Contamination in Traditional Evaluation Benchmarks
Traditional evaluation benchmarks generally use a fixed question bank, which easily leads to the problem of dataset contamination.
For example, many domestic large models love to game the GSM-8K leaderboard. Some companies even use unfair evaluation methods to claim they have surpassed GPT-4, such as using CoT for themselves and few-shot for GPT-4; comparing unaligned models with aligned GPT-4. Details can be seen in my answer “Google releases the latest large model Gemini, including multimodal, three major versions, what are its features? Has it surpassed GPT-4?”
In September last year, someone couldn’t stand the leaderboard gaming behavior due to dataset contamination and wrote a paper “Pretraining on the Test Set Is All You Need”, using only a million-parameter model trained on the test set to achieve perfect evaluation results, completely outperforming all existing large models. This shows that the evaluation method using a fixed question bank is not very reliable.
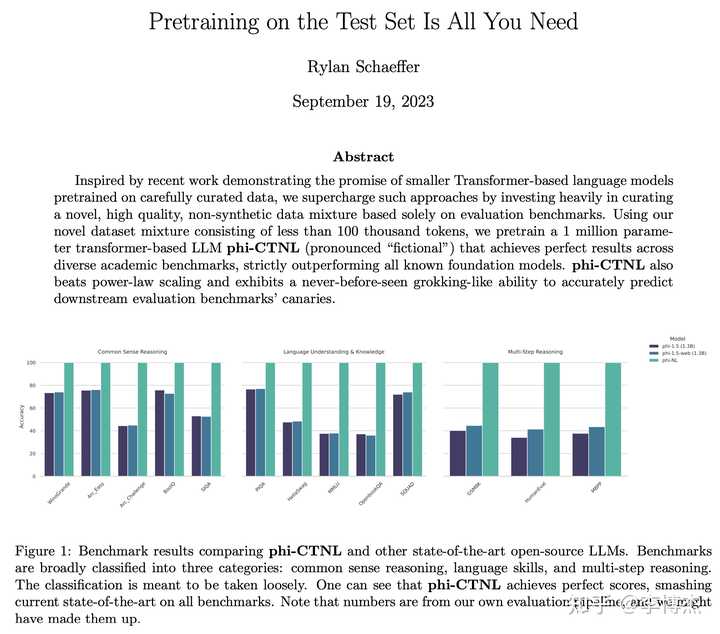
Those who have worked with speech know that the quality of generated speech is basically judged by the MOS score, Mean Opinion Score, which is a subjective human rating. Chatbot Arena utilizes this community evaluation method.
Chatbot Arena allows anonymous users in the community to ask questions to large models, and then two anonymous large models on the left and right each produce a response, and users vote on whether A or B is better. Since both users and large models are anonymous, Chatbot Arena ensures double-blindness.
Evaluation Is Easier Than Generation, and Relative Evaluation Is Easier Than Absolute Evaluation
This community voting mechanism seems simple, but it has a profound philosophical basis: evaluation is easier than generation, and relative evaluation is easier than absolute evaluation.
What OpenAI’s Superalignment aims to ensure is that future superintelligences surpassing human capabilities will obey human intentions. How can a weak intelligence supervise a strong one? Jan Leike, head of the OpenAI Superalignment team, made a famous assertion in 2022: evaluation is easier than generation.
Here I translate the part “evaluation is easier than generation” from Jan Leike’s original text, which can be found here: https://aligned.substack.com/p/alignment-optimism
Evaluation is easier than generation
This principle is important because it allows us to easily obtain meaningful alignment work from systems. If this holds true, it means that if we focus our time and energy on evaluating the behavior of systems rather than doing these tasks ourselves (even if their generative capabilities may not match ours), we can significantly accelerate our research.
This property is the basis of recursive reward modeling (and to some extent, OpenAI’s proposed Debate): If evaluation is easier than generation, then AI-assisted humans will have an advantage over AI generators of comparable intelligence level. As long as this holds true, we can scale to increasingly difficult tasks by creating evaluation signals for AI systems performing these tasks, training AI models. Although recursive reward modeling does not scale indefinitely, it does not need to. It only needs to scale enough to allow us to use it to supervise a large amount of alignment research.
Evaluation being easier than generation is a property that exists in many fields:
Formal problems: Most computer scientists believe NP != P, which means there is a large class of problems that indeed have this property formally. Most of these problems have also empirically shown this property in the algorithms we can think of: SAT solving, graph algorithms, proof searching, model checking, and so on.
Traditional sports and games: Any sport or game worth watching has this property. Not only do spectators need to be able to judge who won the game, but they also need to know who is leading and who is making exciting moves or plays. Therefore, evaluation needs to be simple enough for the majority of spectators to complete. At the same time, generation (playing the game skillfully) needs to be difficult enough so that the best individuals can easily stand out from most people; otherwise, there would be little point in holding the competition. For example: you can judge who is leading in StarCraft by looking at the players’ units and economy; you can judge who is leading in DotA by looking at kill/death stats and earned money; you can judge who is leading in chess by looking at material and position (although evaluating position may be difficult); you can judge who is winning in football or rugby by looking at the scoreboard and which team spends the most time on the field; and so on.
Many consumer products: Comparing the quality of different smartphones is much easier than manufacturing a better smartphone. This applies not only to easily measurable features, such as the amount of RAM or the number of pixels, but also to more nebulous aspects, such as the comfort of holding the phone and the durability of the battery. In fact, this holds true for most (technology) products, which is why people pay attention to Amazon and YouTube reviews. Conversely, for products that are difficult for individual consumers to evaluate and are less regulated by the government, the market is often flooded with low-quality products. For example, nutritional supplements often do not have the benefits they claim, do not contain the claimed amount of active ingredients, or contain unhealthy contaminants. In this case, evaluation requires expensive laboratory equipment, so most people making purchasing decisions do not have reliable signals; they can only take the supplement and see how they feel.
Most jobs: Whenever companies hire employees, they need to know whether these employees truly help them achieve their mission. It is uneconomical to spend as much time and effort evaluating an employee’s job performance as it takes to complete the work; so it can only take much less effort to evaluate job performance. Is this effective? I certainly would not claim that companies can perfectly obtain signals of actual employee performance, but if they cannot evaluate more easily than employees, then efforts like performance improvement, promotions, and dismissals would basically be random and a waste of time. Therefore, companies that do not spend a lot of time and effort evaluating employee performance should outperform others that do.
Academic research: Evaluating academic research is notoriously difficult, and government funding agencies have almost no tools to distinguish between good and bad research: decisions are often made by non-experts, a lot of low-quality work is funded, and proxy indicators such as citation counts and published paper numbers are overly optimized. The NeurIPS experiment famously found a lot of noise in the academic review process, but what is often overlooked is that there is also a lot of meaningful signal: writing a NeurIPS paper usually requires at least several months of full-time work (e.g., >1000 hours), while a review is typically completed in a few hours (for example, 4 reviews each taking 3 hours, totaling 12 hours). However, the review committee’s consistency rate on accept/reject decisions reaches 77%, and on accepting oral presentations/focus-rated papers reaches 94%. Considering the two orders of magnitude difference in effort between generation and evaluation, this is an incredibly high consistency rate (much higher than the consistency rate of data labeling for OpenAI API tasks, which is only 70-80%)! There is much to be said about the corruption of academic incentives and whether NeurIPS papers truly advance human scientific knowledge, but at least for the task of writing a paper that gets into NeurIPS, this seems to hold true.
However, there are some tasks where this principle usually does not hold: writing down your signature is easier than evaluating whether a given doodle is your signature. Encrypting or hashing a picture of a dog is simple, but evaluating whether some given binary data is an encrypted or hashed picture of a dog is very difficult. This makes cryptography possible.
The evidence above does not mean that this principle also applies to alignment research. But it does point in that direction to a large extent. In other words, if evaluating NeurIPS papers is much more difficult than writing them, and reviewers’ opinions do not tend to exceed random levels, shouldn’t we consider this as evidence that alignment research is easy to automate?
More importantly, if evaluating alignment research is not easier than generation, this is also bad news for purely human-driven alignment research: in this case, those who find solutions to alignment problems will not be able to convince others to use the solution, because others will not know whether it is useful. Instead, every AGI developer will need to find a solution for themselves.
Although any proxy indicators for evaluating alignment research may be overly optimized and lead to seemingly persuasive but fundamentally flawed alignment research, this does not mean that there will not still be useful proxy indicators that can be optimized for a while.
However, there is an important caveat: adversarially constructed inputs may be more difficult to evaluate than non-adversarial inputs (although they may still be easier than generation). For example, a superhuman-level Go AI Agent may have simple vulnerabilities. A hypothetical example of alignment research: by controlling only the randomness during the training process, a backdoor can be implanted in the model. Human evaluators unaware of this will miss important flaws in the training code secretly manipulated by the malicious AI system’s randomness source.
Another important open question is, if you cannot rely on feedback signals from the real world, is evaluation still easier than generation? For example, if you are not allowed to run a piece of code, is evaluating a piece of code easier than writing it? If we are concerned that our AI systems are writing code that may contain trojans and break sandboxes, then we cannot run it to “see what happens” before we carefully review it. In this case, rewriting the code may be easier than discovering hidden flaws (as implied by Rice’s theorem, which suggests no defensive advantage).
As Jan Leike pointed out, “evaluation is easier than generation” is very common in everyday life. You don’t need to be a chef to judge whether a dish is delicious, nor do you need to be a professor to evaluate whether a class is taught well.
Not everyone agrees with this view, though. When I was working on the University of Science and Technology course evaluation community in 2015, some people believed that students were not qualified to judge whether a professor’s teaching was good or not.
OpenAI is the first to apply this simple and universal truth to solve one of AI’s and even humanity’s most important issues: how to ensure that superintelligence smarter than humans obeys human intentions.
Following the idea that “evaluation is easier than generation,” by the end of 2023, OpenAI finally published the first research result in the field of superalignment: Weak-to-Strong Generalization, which means using a weaker model to supervise a stronger model, enhancing the performance of the stronger model. Although we do not yet have superhuman intelligence (as shown in the image below, Superalignment), we can use two relatively weaker models for simulation experiments (as shown on the right in the image, Our Analogy). The experimental results prove that the supervision of weaker models can indeed improve the performance of stronger models. This is significantly different from the traditional machine learning where stronger models supervise weaker ones (as shown on the left in the image, Traditional ML), bringing a glimmer of hope to the superalignment, a crucial issue for AI and even humanity.
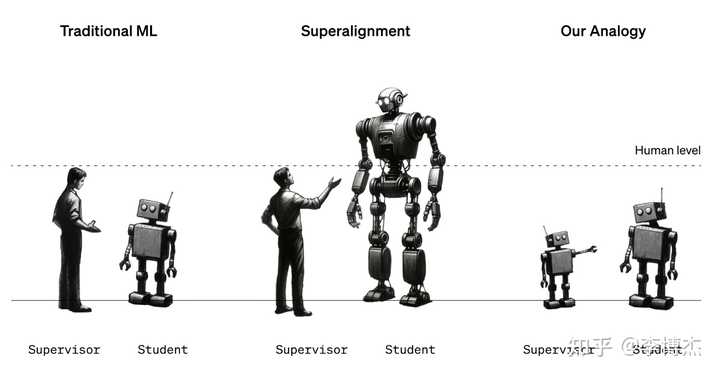 Weak-to-Strong Generalization
Weak-to-Strong Generalization
So why does Chatbot Arena use a model competition arena (Arena) format instead of letting users directly rate the quality of model outputs? There is a philosophical basis for this: Relative evaluation is easier than absolute evaluation.
For example, if I am not a designer, it is not easy for me to absolutely evaluate whether a webpage’s design is good or not. But if you give me two design proposals, most people can compare which one is better.
It’s similar with content generated by large models. If we use an absolute scoring method, first, many people find it hard to judge whether the text, images, audio, or videos generated by large models are good or bad, and second, some people like to give high scores, while others prefer low scores. But relative scoring, especially the double-blind relative scoring like in Chatbot Arena, can avoid the difficulties of absolute scoring and the problem of normalizing scores.
Anti-vote rigging mechanisms
To prevent vote rigging, Chatbot Arena uses many mechanisms, including:
- CloudFlare to block bots
- Limiting the number of votes per IP
- If an answer reveals the model’s identity, the user’s vote does not count towards the leaderboard (thus asking “Who are you?” to break the double-blind is not feasible)
Of course, since Chatbot Arena is completely anonymous, it cannot fundamentally prevent Sybil attacks, commonly known as vote rigging. If there are larger economic interests behind Chatbot Arena’s leaderboard, vote rigging becomes a more serious issue to consider.
All user votes on Chatbot Arena, after being cleaned and anonymized, are public. Here is the Google Colab Notebook for processing these user vote data: https://colab.research.google.com/drive/1KdwokPjirkTmpO_P1WByFNFiqxWQquwH#scrollTo=tyl5Vil7HRzd
Download link for user vote data (note that today is April 13, but only data from April 10 is available for download, and the leaderboard is updated to April 11, because the data needs to be cleaned before the public leaderboard can be updated): https://storage.googleapis.com/arena_external_data/public/clean_battle_20240410.json
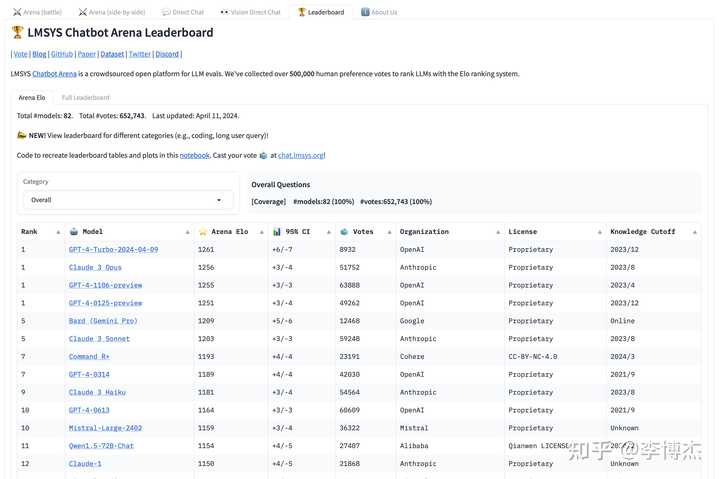
Based on the voting results, using a method similar to the Elo rating system in chess competitions, Chatbot Arena produces a model leaderboard. Community users have also made a video of the changes in the Chatbot Arena leaderboard over the past year, showing that the competition among large models is indeed fierce, with frequent changes in leadership.
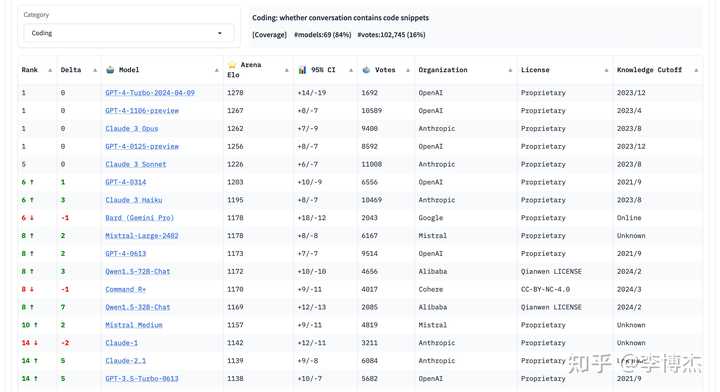
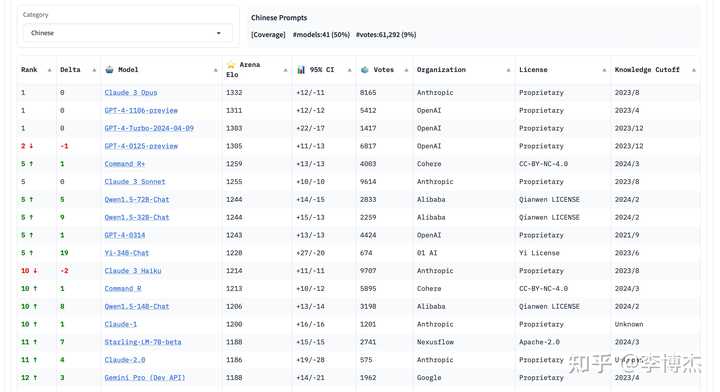
Recently, Chatbot Arena has also added category leaderboards.
For example, code:
Chinese:
Long context:
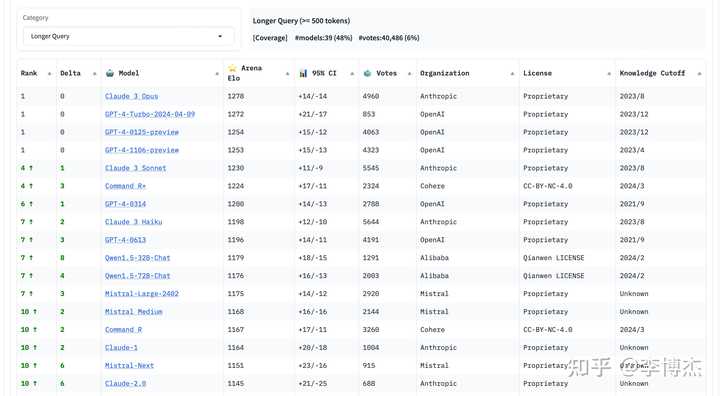
Actually, creating a credible leaderboard is really not easy. To share a bit of personal experience unrelated to Chatbot Arena, when I was working on the leaderboard for the University of Science and Technology course evaluation community, some people said that the least popular courses leaderboard could easily offend people, and suggested keeping only the most popular courses leaderboard. However, we eventually kept both the most and least popular courses leaderboards, and no teacher complained about the leaderboard. Instead, the teachers who wanted us to delete comments did so because of specific comments. In fact, the top 10 most popular teachers identified by the leaderboard matched 7 of the top 10 teachers independently collected by the school’s academic office, indicating high consistency in community evaluations.
In 2022, when I wanted to participate in a mentor evaluation website, my wife strongly opposed it, saying that such websites could easily offend people. Therefore, to run a community evaluation, you must not be afraid of offending people, and you must encourage objective and rational evaluations through mechanism design and operational strategies.
Chatbot Arena’s leaderboard not only did not offend the companies behind these large models, but it has become the official benchmark for various AI companies to promote their models. This is closely related to the mechanism design and operational strategies of Chatbot Arena. First, Chatbot Arena does not let users directly review the models themselves, but allows anonymous users to vote on anonymous model outputs in a double-blind manner, thus avoiding biased polarized reviews and ensuring the platform’s fairness. Secondly, Chatbot Arena’s official Twitter often congratulates various models on their ranking improvements and new model evaluation results, providing publicity material for the companies behind these models.
A Brief History of Chatbot Arena
@SIY.Z and other UC Berkeley PhDs foresaw the rapid evolution and proliferation of large models when GPT-4 was just released last year, and quickly launched Chatbot Arena.
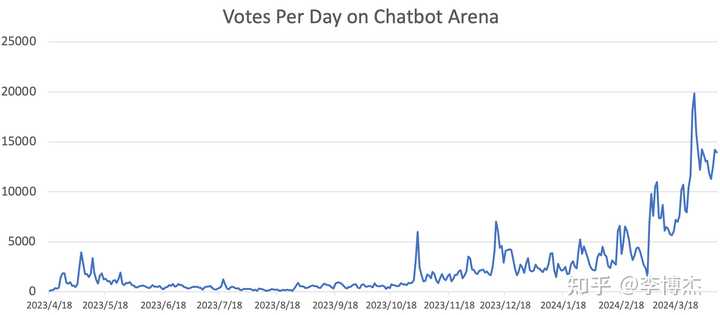
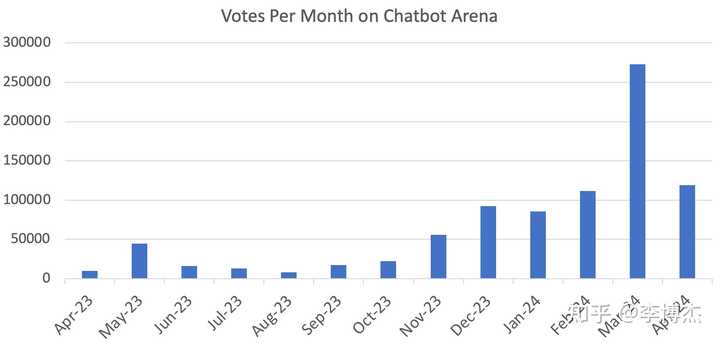
On April 18, 2023, Chatbot Arena officially went live, with only 113 votes that day. Today, Chatbot Arena receives tens of thousands of votes daily. In less than a year, there have been 650,000 votes.
Chatbot Arena experienced two explosive growth periods in popularity, the first in November 2023, when the release of GPT-4-Turbo brought a wave of popularity, followed by tweets from OpenAI’s Greg Brockman, Google’s Jeff Dean, and OpenAI’s Andrej Karpathy.
The second explosive growth in popularity was in March 2024, as mentioned at the beginning of this article, when several large models took turns on stage—Google, Anthropic, Mistral each demonstrated the capability to compete with OpenAI’s GPT-4, even Cohere’s open-source Command R+ took on GPT-4.