网络虚拟化技术大观
网络虚拟化(Network Virtualization)就是搭建一个与物理网络拓扑结构不同的虚拟网络。例如公司在世界各地有多个办事处,但希望公司的内部网络是一个整体,就需要网络虚拟化技术。
从 NAT 说起

假设北京办事处的一台机器 IP 是 10.0.0.1(这是一个内网 IP,不可以在 Internet 上使用),上海办事处的一台机器 IP 是 10.0.0.2,它们要通过 Internet 通信。北京办事处的公网(Internet)IP 是 1.1.1.1,上海办事处的公网 IP 是 2.2.2.2。
一种简单的方式是,在北京办事处的边界路由器(Edge Router)把出去的数据包源 IP 10.0.0.1 变成 1.1.1.1,目的 IP 10.0.0.2 变成 2.2.2.2;把进来的数据包目的 IP 1.1.1.1 变成 10.0.0.1,源 IP 2.2.2.2 变成 10.0.0.2。在上海办事处的边界路由器做类似的地址翻译。这样 10.0.0.1 和 10.0.0.2 就能通信了,它们完全不知道 Internet 和地址翻译过程的存在。这就是基本的 NAT(Network Address Translation)。

不过这种做法有严重的问题。设想上海办事处增加了一台机器,内网 IP 为 10.0.0.3。不管北京办事处那边怎么处理,上海办事处的边界路由器收到一个目的 IP 为 2.2.2.2 的数据包,该发给 10.0.0.2 还是 10.0.0.3 呢?这种 bug 看起来很简单,但却是设计者很容易忽略的。设计网络拓扑或网络协议时,不能光想着数据包怎么出去,还得想好回复的数据包怎么进来。使用简单 NAT 的话,每增加一台内网机器,就要在边界路由器上增加一个公网 IP。
我们知道公网 IP 是很宝贵的,NAPT(Network Address and Port Translation)应运而生。Linux 里的 NAT 事实上是 NAPT。出去和进来的连接需要分别考虑。对于进来的连接,NAPT 的基本假设是共享同一公网 IP 的两台机器不会提供相同的服务。例如 10.0.0.2 提供 HTTP 服务,10.0.0.3 提供 HTTPS 服务,则上海办事处的边界路由器可以配置成 “目的 IP 是 2.2.2.2 且目的端口是 80(HTTP)的发到 10.0.0.2,目的端口是 443(HTTPS)的发到 10.0.0.3”。这就是 DNAT(Destination NAT)。
对于出去的连接,事情就稍微复杂一些。10.0.0.2 发起了一个到 10.0.0.1 的连接,其源端口是 20000目的端口是 80。10.0.0.3 也发起了一个到 10.0.0.1 的连接,其源端口是 30000,目的端口也是 80。当一个来自北京办事处的回复包到达上海办事处的边界路由器时,其源端口是 80,目的端口是 20000,如果边界路由器不保存连接状态,显然不知道这个包该转给谁。也就是边界路由器要维护一张表:

当一个回复包过来的时候,查源端口(80)和目的端口(20000),匹配上第一条记录,知道该发给 10.0.0.2。为什么需要“新的源端口”这一列呢?如果 10.0.0.2 和 10.0.0.3 分别以相同的源端口发起了到相同目的 IP、相同目的端口的 TCP 连接,这两个连接的回复包将无法区分。这种情况下,边界路由器必须分配不同的源端口,实际发出去的包的源端口就是“新的”。对出去的连接做网络地址转换叫做 SNAT(Source NAT)。
IP-in-IP 隧道
NAPT 要求共享公网 IP 的两台机器不能提供相同的服务,这个限制很多时候是不可接受的。比如我们经常需要 SSH 或远程桌面到每一台机器上。隧道技术应运而生。最简单的三层隧道技术是 IP-in-IP。

如上图,白底黑字的是原始 IP 数据包,蓝底白字的是加上去的头部。这个头部一般在发送方的边界路由器上被加上(encap)。加上去的头部首先是二层(Link Layer)头部,然后是三层(Network Layer)头部,整个包是一个合法的 IP 包,是可以在 Internet 中路由的。接收方的边界路由器收到这个包后,看到加上去的头部中有 IP-in-IP 标志(IP protocol number = 0x04,图中未显示),就知道这是一个 IP-in-IP tunnel 的数据包;又看到 Public DIP 是自己,就知道该解包(decap)了。解包之后,原始包(Private SIP,Private DIP)就露出来了,再路由到内网的对应机器。
IP-in-IP Tunneling 是不够的。
- 如果你尝试用 IP-in-IP tunneling 搭建一个隧道两端有相同网络地址和子网掩码的局域网,不在客户端上配置 ARP 表的话,会发现客户端(注意不是隧道两端的路由器)之间 ping 不通。因为在发 ping 包(ICMP echo request)之前,系统要通过 ARP 协议得到对方的 MAC 地址,才能正确填写二层(link layer)头。IP-in-IP tunnel 只能通过 IPv4 包,不能通过 ARP 包。(IPv4 和 ARP 是不同的三层协议)因此,客户端上必须手工配置 ARP 表,或者让路由器代为回答,增加了网络配置的难度。
- 在数据中心里,往往不止一个客户。例如两个客户都创建了虚拟网络,内网 IP 都是 10.0.0.1,如果它们在发往 Internet 时共享相同的 Public IP,则对一个进来的 IP-in-IP 数据包,无法判断该发给哪个客户。
- 如果要做负载均衡(load balancing),一般是对包头五元组(源 IP、目的 IP、四层协议、源端口、目的端口)做 hash,根据 hash 值选定目标机器,这样可以保证同一连接的数据包总是被发往同一机器。如果做负载均衡的普通网络设备收到一个 IP-in-IP 数据包,如果不认识 IP-in-IP 协议,则无法解析四层协议和端口号,只能根据 Public SIP 和 Public DIP 做 hash,Public DIP 一般是相同的,那么只有源 IP 一个变量,hash 的均匀性很难保证。
第一个问题,说明被打包(encap)的数据包不一定是 IP 包。第二个问题,说明可能需要添加额外的识别信息。第三个问题,说明被加上去的包头也不一定是 IP 包头。网络虚拟化技术之所以“百花齐放”而不是 one size fits all,就是这个道理。
网络虚拟化技术的分类
看一种网络虚拟化技术,主要是看隧道里包的格式。
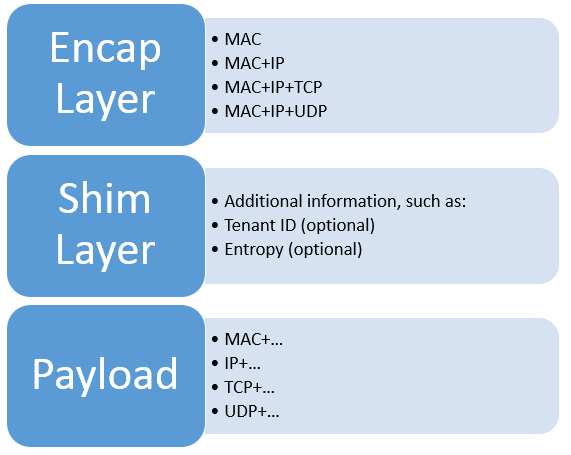
- 最外层的是封装层(encapsulation layer),由于需要在网络中传输,必须是合法的二层数据包,因此最外层必须是 MAC。当我们说封装层是 N 层时,意味着加上去了 2 … N 层封装包头。
- 中间的是可选的夹层(shim layer),包含了一些附加信息和标志位,例如用于标识不同客户的虚拟网络的 Tenant ID,以及用于提高 hash 均匀性的熵(Entropy)。
- 内层的是客户实际发送的数据包,这一层决定了虚拟网络在客户看来是长什么样的。例如 IP-in-IP tunnel 的内层是 IPv4 包,则在客户看来虚拟网络就是个 IPv4 网络,里面跑 TCP、UDP、ICMP 或者任何其他四层协议都行。当我们说虚拟网络是 N 层时,意味着客户所发包的 2 .. N-1 层不会被传输(这些层次有可能影响封装层,也就是进入哪条隧道)。虚拟网络并不是层次越低(越靠近物理层)越好,因为越底层的协议越难优化,这一点我们稍后会看到。
 Capture
Capture
根据隧道里包的格式,可以把常见的网络虚拟化技术(我把一些隧道技术也算在网络虚拟化技术的范畴里了)做个简单分类:(下述 PPP 和 MAC 是二层协议,IP 是三层协议,TCP 和 UDP 是四层协议)
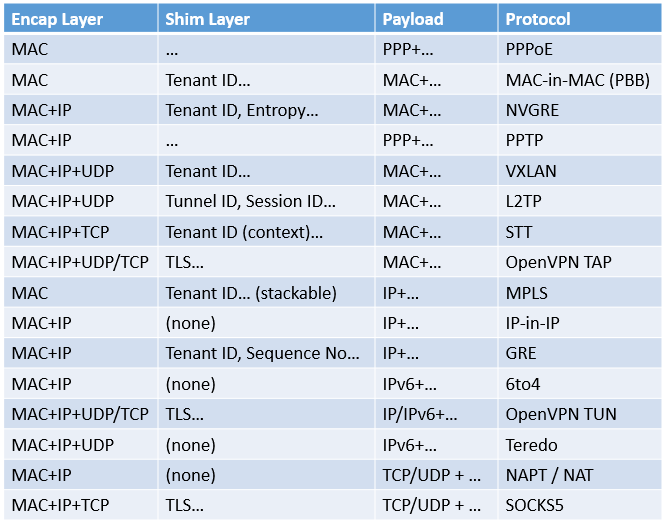
由此可见,几乎各种合理的 Encap Layer 与 Payload 的组合,都有对应的协议。因此,有的人 “给 GRE 加一个二层头,就可以……了” 的说法是没有意义的,Encap Layer 和 Payload 一变,就是其他协议了。下面以一些协议为例,说明不同层次协议存在的意义,也就是它解决了什么问题。
GRE vs. IP-in-IP
GRE(Generic Routing Encapsulation)协议比 IP-in-IP 协议增加了一个中间层(shim layer),包括 32 位的 GRE Key(Tenant ID 或 Entropy)和序列号等信息。GRE Key 解决了前面 IP-in-IP tunnel 的第二个问题,使得不同的客户可以共享同一个物理网络和一组物理机器,这在数据中心中是重要的。

NVGRE vs. GRE
GRE 虚拟出来的网络是 IP 网络,这就意味着 IPv6 和 ARP 包不能在 GRE 隧道中传输。IPv6 的问题比较容易解决,只要修改 GRE header 中的 Protocol Type 就行。但 ARP 的问题就不那么简单了。ARP 请求包是广播包:“Who has 192.168.0.1? Tell 00:00:00:00:00:01”,这反映了二层与三层网络的一个本质区别:二层网络是支持广播域(Broadcast Domain)的。所谓广播域,就是一个广播包应该被哪些主机收到。VLAN 是实现广播域的常用方式。
当然,IP 也支持广播,不过发往三层广播地址(如 192.168.0.255)的包仍然是发往二层的广播地址(ff:ff:ff:ff:ff:ff),通过二层的广播机制实现的。如果我们非要让 ARP 协议在 GRE 隧道中工作,也不是不行,只是大家一般不这么做。
为了支持所有现有的和未来可能有的三层协议,并且支持广播域,就需要客户的虚拟网络是二层网络。NVGRE 和 VXLAN 是两种最著名的二层网络虚拟化协议。
NVGRE(Network Virtualization GRE)相比 GRE 的本质改动只有两处:
内层 Payload 是二层 Ethernet 帧而非三层 IP 数据包。注意,内层 Ethernet 帧末尾的 FCS(Frame Check Sequence)被去掉了,因为封装层已经有校验和了,而计算校验和会加重系统负载(如果让 CPU 计算的话)。
中间层的 GRE key 拆成两部分,前 24 位作为 Tenant ID,后 8 位作为 Entropy。
有了 NVGRE,为什么还要用 GRE 呢?抛开历史和政治原因,虚拟网络的层次越低,越不容易优化。如果虚拟网络是二层的,由于 MAC 地址一般是非常零散的,只能给每台主机插入一条转发规则,网络规模大了就是问题。如果虚拟网络是三层的,就可以根据网络拓扑分配 IP 地址,使得网络上临近的主机 IP 地址也在同一子网中(Internet 正是这样做的),这样路由器上只需根据子网的网络地址和子网掩码前缀匹配,能减少大量的转发规则。
如果虚拟网络是二层的,ARP 广播等包就会广播到整个虚拟网络,因此二层网络(我们常说的局域网)一般不能太大。如果虚拟网络是三层的,由于 IP 地址是逐级分配的,就不存在这个问题。
如果虚拟网络是二层的,交换机要依赖生成树(spanning tree)协议以避免环路。如果虚拟网络是三层的,就可以充分利用路由器间的多条路径增加带宽和冗余性。数据中心的网络拓扑一般如下图所示(图片来源)
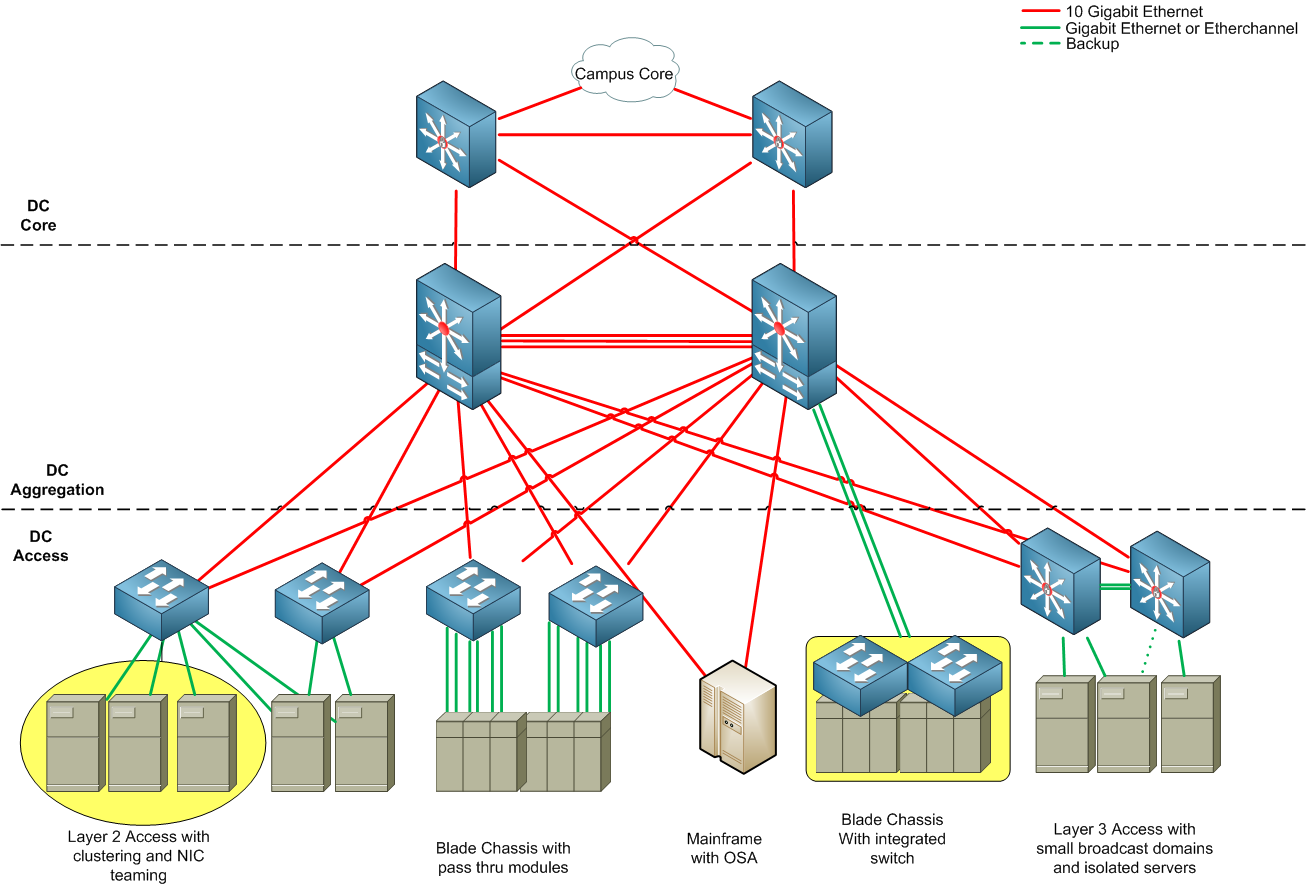 Data-Center-Design
Data-Center-Design
虚拟网络的层次如果更高,payload 里不包括网络层,一般就不能称之为“虚拟网络”了,但仍然属于隧道技术的范畴。SOCKS5 就是这样一种 payload 是 TCP 或 UDP 的协议。它的配置灵活性比基于 IP 的隧道技术更高,例如可以指定 80 端口(HTTP 协议)走一个隧道,443 端口(HTTPS 协议)走另一个隧道。ssh 的 -L(本地转发)、-D(动态转发)参数用的就是 SOCKS5 协议。SOCKS5 的缺点则是不支持任意的三层协议,如 ICMP 协议(SOCKS4 甚至不支持 UDP,因此 DNS 处理起来比较麻烦)。
VXLAN vs. NVGRE
NVGRE 虽然有 8 位的 Entropy 域,但做负载均衡的网络设备如果不认识 NVGRE 协议,仍然根据 “源 IP、目的 IP、四层协议、源端口、目的端口” 的五元组来做 hash,这个 entropy 仍然派不上用场。
VXLAN(Virtual Extensible LAN)的解决方案是:封装层除了 MAC 和 IP 层,再增加一个 UDP 层,使用 UDP 源端口号作为 entropy,UDP 目的端口号作为 VXLAN 协议标识。这样负载均衡设备不需要认识 VXLAN 协议,只要把这个包按照正常的 UDP 五元组做 hash 就行。

上图:VXLAN 封装后的数据包格式(图片来源)
VXLAN 的夹层比 GRE 的夹层稍简单,仍然是用 24 位作为 Tenant ID,没有 Entropy 位。添加包头的网络设备或者操作系统虚拟化层一般是把内层 payload 的源端口(source port)复制一份,作为封装层的 UDP 源端口。由于发起连接的操作系统在选择源端口号时,一般是顺序递增或者随机,而网络设备内部的 hash 算法一般就是 XOR,这样得到的 hash 均匀性一般比较好。
STT vs. VXLAN
STT(Stateless Transport Tunneling)是 2012 年新提出的、仍然处于草案状态的网络虚拟化协议。STT 与 VXLAN 相比,初看起来只是把 UDP 换成了 TCP,事实上如果在网络上抓经过 STT 与 VXLAN 打包的数据包,是大不相同的。
STT 为什么要用 TCP 呢?事实上 STT 只是借了个 TCP 的壳,根本没有用 TCP 的状态机,更不用说确认、重传和拥塞控制机制了。STT 想借用的是现代网卡的 LSO(Large Send Offload)和 LRO(Large Receive Offload)机制。LSO 使得发送端可以生成长达 64KB(甚至更长)的 TCP 包,由网卡硬件把大包的 TCP payload 部分拆开,复制 MAC、IP、TCP 包头,组成可以在二层发送出去的小包(如以太网的 1518 字节,或者开启了 Jumbo Frame 的 9K 字节)。LRO 使得接收端可以把若干个同一 TCP 连接的小包合并成一个大包,再生成一个网卡中断发送给操作系统。
如下图所示,Payload 在被发送出去之前,要加上 STT Frame Header(中间层)和 MAC header、IP header、TCP-like header(封装层)。网卡的 LSO 机制会把这个 TCP 包拆成小块,复制封装层添加到每个小块前面,再发送出去。

我们知道用户-内核态切换和网卡中断是很消耗 CPU 时间的,网络程序(如防火墙、入侵检测系统)的性能往往是以 pps(packet per second)而不是 bps(bit per second)计算的。那么在传送大量数据时,如果数据包可以更大,系统的负载就能减轻。
STT 最大的问题是不容易在网络设备上实施针对某个客户(tenant ID)的策略。如上图所示,对于一个大包,只有第一个小包头部有 STT Frame Header,而后续的小包里没有可以标识客户的信息。如果我要限制某个客户从香港数据中心到芝加哥数据中心的流量不超过 1Gbps,就是不可实现的。如果使用其他网络虚拟化协议,由于每个包里都有标识客户的信息,这种策略只要配置在边界路由器上即可(当然边界路由器需要认识这种协议)。
结语
本文以 IP-in-IP、GRE、NVGRE、VXLAN、STT 等协议为例,介绍了百花齐放的网络虚拟化技术。学习一种网络虚拟化技术时,首先要弄清楚它的封装层次、虚拟网络的层次和中间层所包含的信息,并与其他类似协议进行比较,然后再看标志位、QoS、加密等细节。选用网络虚拟化技术时,也要根据操作系统和网络设备的支持程度和客户网络的规模、拓扑、流量特征综合考虑。