Bojie Li (李博杰)
2024-02-07
(本文转载自 甲子光年公众号,感谢甲子光年的采访)

总结 2023,启程 2024。
作者|刘杨楠 苏霍伊 赵健
最近一两周,很多公司都在紧锣密鼓地开战略会,明确 2024 年的目标与规划。
经过一年多 AI 狂飙带来的推背感,是时候给忙碌的 2023 年做一个年终总结了。开完战略会、进入春节假期,大部分公司才会真正停下步履不停的脚步,进入短暂而难得的休息状态。
那么,如何总结 2023 年呢?
「甲子光年」邀请了基础大模型、AI Infra(AI 基础设施)、多模态、行业垂直场景与学术研究等领域的 30 多位 AI 从业者,分别抛出了 5 个问题:
2023 年你的关键词是什么?
2023 年你所经历的 Magic Moment(印象最深刻的一个瞬间)是什么时候?
2023 年你是否在一轮又一轮的技术冲击中彷徨过?从彷徨到豁然开朗,中间的转折点是什么?
预测一下 2024 年 AI 行业可能发生的重要事件?
如果对一年前的自己说一句话,你会说什么?如果向一年后的自己问一个问题,你会问什么?
他们的彷徨与焦虑、激动与兴奋,是 AI 行业一整年的缩影;他们的探索与坚持、刷新与迭代,将是未来五年甚至十年 AI 大爆炸的前奏。
以下是他们的分享(按姓名首字母排序)。
2024-02-03
早在 2021 年就预订了韩国艺匠的婚纱照,想去科大拍婚纱照,但是疫情之后科大就一直不让校外人员进校了。好在韩国艺匠是全国连锁的,2023 年 8 月我们就改到北京拍了,没有加钱,北京的拍摄环境还比合肥更好。
视频电子相册(03:54,150 MB)
2024-02-03
(本文是 2024 年 1 月 6 日笔者在知乎首届 AI 先行者沙龙上的演讲实录)

非常荣幸能够认识大家,非常荣幸能够来知乎 AI 的先行者沙龙来做分享,我是李博杰,Logenic AI 联合创始人。我们知道目前 AI Agent 非常火,比如说参加路演 70 多个项目,一半多都是跟 AI Agents 相关的项目, AI Agents 的未来会是什么样子呢?它未来应该是更有趣还是更有用呢?
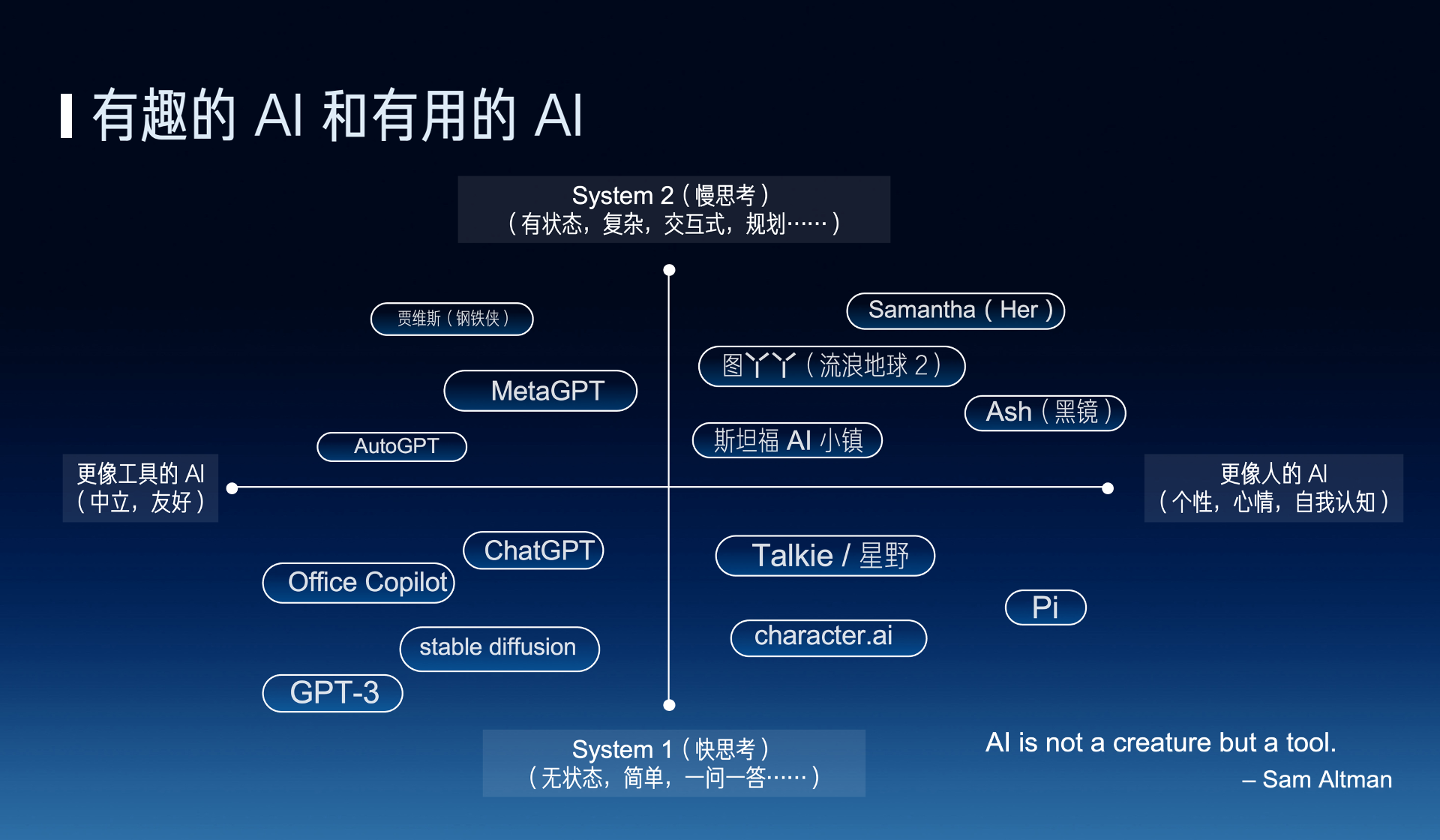
我们知道 AI 的发展目前一直有两个方向,一个是有趣的 AI,一个是更像人的 AI,另外一个方向就是更有用的 AI,也就是 AI 应该更像人还是更像工具呢?其实是有很多争议的。比如说 OpenAI 的 CEO Sam Altman 他就说 AI 应该是一个工具,它不应该是一个生命,但是我们现在所做的事正好相反,我们现在是让 AI 其实更像人,其实很多科幻电影里的 AI 其实更像人,比如说 Her 里面的 Samantha,还有《流浪地球 2》里面的图丫丫,黑镜里面的 Ash,所以我们希望能把这些科幻中的场景带到现实。
除了有趣和有用这两个方向之外,还有另外一个上下的维度,就是快思考和慢思考,有一本书叫《思考,快与慢》,它里面就说人的思考可以分为快思考和慢思考,也就是所谓的快思考就是人下意识的想,不需要过脑子的,像 ChatGPT 这种一问一答的可以认为是一种快思考,因为你不问它问题的时候,它不会主动去找你,而慢思考呢,就是有状态的这种复杂的思考,也就是说如何去规划和解决一个复杂的问题,做什么、后做什么。
2024-01-27
(视频包含 96 张照片,06:24,190 MB)
2024-01-08
(转载自搜狐科技,作者:梁昌均)
编者按:
人生重燃,如春柳抽芽,历经寒冬的磨砺,终焕生机。
每个人都是航行者,在人生的旅途中,我们难免遭遇困境、挫折和失败。面对风浪的洗礼,我们不断调整航向,坚定前行,寻找属于自己的彼岸。
人生重燃,亦是对自我价值的重新认识。我们要学会欣赏自己的优点,如琴瑟之和谐,亦接受自己的不足,如同璞玉需经琢磨方显光华。
此路虽不易,但如清泉之在石,日积月累,终汇聚成海。
值此跨年之际,搜狐财经、搜狐科技联合推出策划报道,聚焦个体小人物的人生重燃之旅,一起勇敢面对人生挑战。
2023-12-23
经常有人让我推荐一些 AI Agent 和大模型相关的经典论文,在这里列一些对我比较有启发的 paper,可以作为 Reading List。
这里面大部分的 paper 都是今年刚发表的,但是也有一些文本大模型、图片视频生成模型的经典论文,把这些经典论文读明白是理解大模型的关键。
这些论文如果都读完了,哪怕是只领会了论文的核心 idea,也保证能让你不再仅仅是一名 prompt 工程师,而能够跟大模型的专业研究者深入讨论了。
2023-12-22
(转载自科大新创校友基金会)

12 月 21 日,中国科大北京校友 AI 沙龙在中国科学院网络信息中心进行,曾经的华为“天才少年”、Logenic AI 联合创始人李博杰 (1000)做《AI Agent 的下一站:有趣还是有用?》主题报告,与线上、线下累计近 200 位同学、校友分享。
主题报告
报告围绕《AI Agent:有用还是有趣》主题展开,结合具体的生活、工作场景,在 “有趣” 角度,分析了如何低成本地实现 AI agent 的长期记忆以及如何建模人的内部思考过程等问题;在 “有用” 角度,对于如何实现 AI agent 的图片理解、复杂任务规划与分解和如何减少幻觉等问题展开讨论。此外,他还对于如何降低大模型的推理成本提出了自己的看法。
2023-12-16
(本文首发于知乎)
利益无关:因为我没有在做基础大模型(做的是 infra 和应用层),目前也没有做国内市场,所以可以从相对中立的角度提供一些信息。
创业几个月,发现可以比普通大厂员工拿到多很多的信息,从投资人和全球 top AI 公司的核心成员那里可以学到很多。综合在美国三个月得到的信息,感觉大厂里面最有前途的是字节和百度,已经公开发布大模型的创业公司里面最有前途的是智谱和 moonshot。
虽然 Robin 说国内已经有上百家做基础大模型的,但由于基础大模型本身是相对同质化的产品,最后基础大模型的市场很可能像公有云一样,top 3 占据大部分的市场,其他的市场份额只能算是 others。
目前国内大多数大模型创业公司才刚开始半年,一切都还没有尘埃落定,有些隐藏的高手还在默默憋大招。大模型的时代才刚刚开始,留得青山在,不怕没柴烧。
2023-12-08
(本文首发于知乎)
演示视频剪辑,技术报告刷榜,模型 API 关键词过滤,Gemini 简直成了大模型发布的段子……
技术报告刷榜
刚刚跟我们 co-founder 思源讨论了下,他是 evaluation 的老手,印证了我的猜测。
首先跟 GPT-4 对比的时候,竟然是自己用 CoT,GPT-4 用 few-shot,这本身就不公平。CoT(思维链)可以显著提升推理能力。有没有 CoT 的区别,就好像考试的时候一个人允许用草稿纸,另一个人只允许口算。
更夸张的是,用了 CoT@32,也就是每个问题回答 32 次,选出其中出现次数最多的那个答案作为输出。也就是说明 Gemini 的幻觉很严重,同一个问题回答准确率不高,所以才需要重复回答 32 次选出现次数最多的。生产环境中真要这么搞,成本得多高呀!
2023-12-06
(本文首发于知乎)
GPT 时刻还难说,但是 LVM 确实是个很有趣的工作。之所以这个工作还没发布源码就已经收获这么多关注,这两天跟我聊的很多人都提到这个工作,根本原因是 LVM 跟大家想象中的端到端视觉大模型架构很类似,我猜测 GPT-4V 可能也是类似的架构。
现在的多模态大模型原理基本上都是一个固定的文本大模型(比如 llama)接上一个固定的 encoder,一个固定的 decoder,中间训练一个薄薄的 projection layer(胶水层)把 encoder/decoder 和中间的 transformer 粘起来。MiniGPT-4,LLaVA,最近的 MiniGPT-v2(还加了 Meta 的作者,值得看看)都是这个思路。
这些现有的多模态大模型 demo 效果不错,但是有一些根本的问题。例如,语音识别的准确率不高,语音合成的清晰度也不高,比不上专门干这个的 Whisper 和 vits。图片生成的精细度也比不上 stable diffusion。更别谈输入和输出图像或语音之间需要做精确对应的任务了,例如把输入图像中的 logo 放到根据 prompt 生成的输出图像上,或者做 xtts-v2 这样的 voice style transfer。这是一个有趣的现象,虽然理论上这个 projection layer 可以建模更复杂的信息,但实际效果还不如使用文本作为中间表达的准确率高。
其根本原因就是文本大模型训练的过程中缺失图像信息,导致编码空间不匹配。就好像一个先天盲人,就算读了再多文字,有些关于色彩的信息仍然是缺失的。
所以我一直认为多模态大模型应该在预训练阶段就引入文本、图像和语音数据,而不是分别预训练各种模态的模型,再把不同模态的模型拼接起来。