Brian (Bojie) Li
2024-04-15
(This article was first published on Zhihu answer: “How to develop research taste in the field of computer systems?”)
In the blink of an eye, it’s been nearly 10 years since I graduated from USTC. Yesterday, while discussing with my wife the recent developments of our classmates in the USTC systems circle, I realized that research taste is the most critical factor in determining academic outcomes. The second key factor is hands-on ability.
What is research taste? I believe that research taste is about identifying influential future research directions and topics.
Many students are technically strong, meaning they have strong hands-on skills and system implementation abilities, but still fail to produce influential research outcomes. The main reason is poor research taste, choosing research directions that either merely chase trends without original thought or are too niche to attract attention.
PhD Students’ Research Taste Depends on Their Advisors
I believe that research taste initially depends heavily on the advisor, and later on one’s own vision.
2024-04-14
(This article was first published on Zhihu Answer: “What are the current benchmarks for evaluating large language models?”)
We must praise our co-founder @SIY.Z for Chatbot Arena!
Chatbot Arena is a community-based evaluation benchmark for large models. Since its launch a year ago, Chatbot Arena has received over 650,000 valid user votes.
Chatbot Arena Witnesses the Rapid Evolution of Large Models
In the past month, we have witnessed several very interesting events on Chatbot Arena:
- Anthropic’s release of Claude-3, with its large Opus model surpassing GPT-4-Turbo, and its medium Sonnet and small Haiku models matching the performance of GPT-4. This marks the first time a company other than OpenAI has taken the top spot on the leaderboard. Anthropic’s valuation has reached $20B, closely approaching OpenAI’s $80B. OpenAI should feel a bit threatened.
- Cohere released the strongest open-source model to date, Command R+, with a 104B model matching the performance of GPT-4, although still behind GPT-4-Turbo. Earlier this year, I mentioned the four major trends for large models in 2024 during an interview with Jiazi Guangnian (“AI One Day, Human One Year: My Year with AI | Jiazi Guangnian”): “Multimodal large models capable of real-time video understanding and generating videos with complex semantics; open-source large models reaching GPT-4 level; the inference cost of GPT-3.5 level open-source models dropping to one percent of the GPT-3.5 API, making it cost-effective to integrate large models; high-end smartphones supporting local large models and automatic app operation, making everyone’s life dependent on large models.” The first is Sora, the second is Command R+, both have come true. I still hold this view, if a company mainly focused on foundational models cannot train a GPT-4 by 2024, they should stop trying, wasting a lot of computing power, and not even matching open-source models.
- Tongyi Qianwen released a 32B open-source model, almost reaching the top 10, performing well in both Chinese and English. The cost-effectiveness of the 32B model is still very strong.
- OpenAI was surpassed by Anthropic’s Claude Opus, and naturally, they did not show weakness, immediately releasing GPT-4-Turbo-2024-04-09, reclaiming the top spot on the leaderboard. However, OpenAI has been slow to release GPT-4.5 or GPT-5, and the much-anticipated multimodal model has not yet appeared, which is somewhat disappointing.
2024-04-07
This video is an interview with me by the Bilibili uploader “Apple Bubbles”, original video link
The entire interview lasted half an hour, recorded in one take, with no edits except for the intro added by the uploader, and no prepared answers to the questions.
(27:07, 136 MB)
2024-03-29
(The full text is about 40,000 words, mainly from a 2-hour report at the USTC Alumni AI Salon on December 21, 2023, and is a technical extended version of the 15-minute report at the Zhihu AI Pioneers Salon on January 6, 2024. The article has been organized and expanded by the author.)
- Should AI Agents Be More Entertaining or More Useful: Slides PDF
- Should AI Agents Be More Entertaining or More Useful: Slides PPTX

I am honored to share some of my thoughts on AI Agents at the USTC Alumni AI Salon. I am Li Bojie, from the 2010 Science Experimental Class, and I pursued a joint PhD at USTC and Microsoft Research Asia from 2014 to 2019. From 2019 to 2023, I was part of the first cohort of Huawei’s Genius Youth. Today, I am working on AI Agent startups with a group of USTC alumni.
Today is the seventh day since the passing of Professor Tang Xiaou, so I specially set today’s PPT to a black background, which is also my first time using a black background for a presentation. I also hope that as AI technology develops, everyone can have their own digital avatar in the future, achieving eternal life in the digital world, where life is no longer limited and there is no more sorrow from separation.
AI: Entertaining and Useful
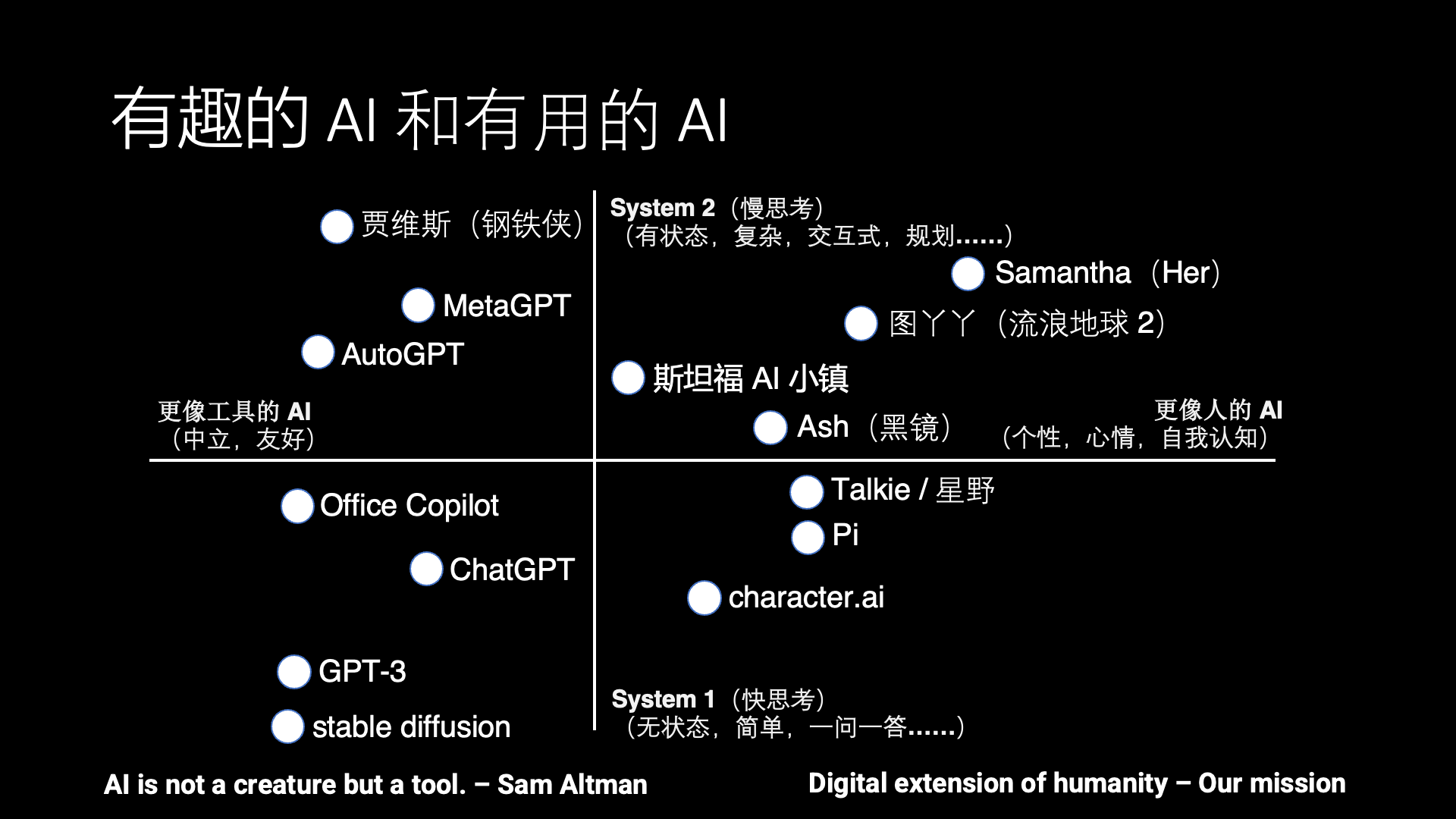
The development of AI has always had two directions, one is entertaining AI, which is more human-like, and the other is useful AI, which is more tool-like.
Should AI be more like humans or more like tools? Actually, there is a lot of controversy about this. For example, Sam Altman, CEO of OpenAI, said that AI should be a tool, not a life form. However, many sci-fi movies depict AI that is more human-like, such as Samantha in Her, Tu Ya Ya in The Wandering Earth 2, Ash in Black Mirror, so we hope to bring these sci-fi scenarios to reality. Only a few sci-fi movies feature tool-like AI, such as Jarvis in Iron Man.
Besides the horizontal dimension of entertaining and useful, there is another vertical dimension, which is fast thinking and slow thinking. This is a concept from neuroscience, from the book “Thinking, Fast and Slow,” which says that human thinking can be divided into fast thinking and slow thinking.
Fast thinking refers to basic visual and auditory perception abilities and expressive abilities like speaking that do not require deliberate thought, like ChatGPT, stable diffusion. These are tool-like fast thinking AIs that respond to specific questions and do not initiate interaction unless prompted. Whereas Character AI, Inflection Pi, and Talkie (Hoshino) simulate conversations with a person or anime game character, these conversations do not involve solving complex tasks and lack long-term memory, thus they are only suitable for casual chats and cannot help solve problems in life and work like Samantha in Her.
Slow thinking refers to stateful complex thinking, which involves planning and solving complex problems, determining what to do first and what to do next. For example, MetaGPT writing code simulates the division of labor in a software development team, and AutoGPT breaks down a complex task into many stages to complete step by step. Although these systems still have many practical issues, they already represent a nascent form of slow thinking capability.
Unfortunately, there are almost no products in the first quadrant that combine slow thinking with human-like attributes. Stanford AI Town is a notable academic attempt, but there is no real human interaction in Stanford AI Town, and the AI Agent’s daily schedule is pre-arranged, so it is not very interesting.
Interestingly, most of the AI in sci-fi movies actually falls into this first quadrant. Therefore, this is the current gap between AI Agents and human dreams. Therefore, what we are doing is exactly the opposite of what Sam Altman said; we hope to make AI more human-like while also capable of slow thinking, eventually evolving into a digital life form.
2024-02-25
Since December 2023, I have been working as a corporate mentor in collaboration with Professor Junming Liu from USTC on an AI Agent practical project, with about 80 students from across the country participating. Most of them are undergraduates with only basic programming skills, along with some doctoral and master’s students with a foundation in AI.
In December 2023 and January 2024, we held 6 group meetings to explain the basics of AI Agents, how to use the OpenAI API, this AI Agent practical project, and to answer questions students had during the practice. The practical project includes:
- Corporate ERP Assistant
- Werewolf
- Intelligent Data Collection
- Mobile Voice Assistant
- Meeting Assistant
- Old Friends Reunion
- Undercover
From February 20-24, some students participating in this research project gathered in Beijing for a Hackathon and presented the interim results of their projects. Participants generally felt the power of large models, surprised that such complex functions could be achieved with just a few hundred lines of code. Below are some of the project outcomes:
2024-02-22
Recently, Groq’s inference chips have made headlines with their large model output speed of 500 tokens/s.
In a nutshell, this chip plays a trick of trading space for time, storing both model weights and intermediate data in SRAM, instead of HBM or DRAM.
This is something I did 8 years ago at Microsoft Asia Research Institute (MSRA), suitable for the neural networks of that time, but really not suitable for today’s large models. Because large models based on Transformers require a lot of memory to store the KV Cache.
Although Groq’s chips have a very fast output speed, due to the limited memory size, the batch size cannot be very large. If we calculate the cost-effectiveness in terms of $/token, it may not be competitive.
Groq needs a cluster of hundreds of cards to run the LLaMA-2 70B model
2024-02-20
My Early Encounters with AI
Meeting AI During My PhD
Originally, my PhD research was focused on networks and systems, with my dissertation titled “High-Performance Data Center Systems Based on Programmable Network Cards“. Many in the field of networks and systems look down upon some AI research, claiming that AI papers are easy to “water down” and that with just an idea, a paper can be published in one or two months. In contrast, top conference papers in networks and systems often require a significant amount of work, taking as long as a year to complete.
Aside from the AI courses I took in school, my first serious AI-related project was in 2016, using FPGA to accelerate neural networks in Bing Ranking. That period was the previous wave of AI hype, and the so-called “four AI dragons” of today all started during that time.
Microsoft deployed FPGAs on a large scale in data centers not only for network virtualization but also for an important piece of neural network inference acceleration. At that time, we also used pipeline parallelism to store all the neural network weights on the FPGA’s SRAM, achieving super-linear acceleration. This story is described in more detail in the section “Exploration of Machine Learning Accelerators” in “Five Years of PhD at MSRA — Leading My First SOSP Paper“.
At that time, many people working in networks and systems didn’t understand AI, nor did they care to understand it, unable to distinguish between training and inference, or forward and backward operators. By optimizing these operators, I at least understood how basic feedforward neural networks (FFNN) work. However, I didn’t get involved in business applications or tinker with my own models.
2024-02-16
A joke is circulating among investors today: “I can finally get a good night’s sleep, because I no longer have to worry about the video generation companies I’ve invested in being overtaken by others.”
Last month, during an interview with Jiazi Light Year, “AI one day, human world one year: My 2023 with AI | Jiazi Light Year,” I predicted the four major trends of 2024, the first of which was video generation. I didn’t expect it to come true so quickly. (Of course, the videos generated by Sora currently do not contain complex semantics, and it cannot generate in real-time, so there’s still a chance for others)
- Multimodal large models can understand videos in real-time and generate videos containing complex semantics in real-time;
- Open-source large models reach the level of GPT-4;
- The inference cost of GPT-3.5 level open-source models drops to one percent of the GPT-3.5 API, alleviating cost concerns when integrating large models into applications;
- High-end phones support local large models and automatic App operations, making everyone’s life inseparable from large models.
Video Generation Models as World Simulators
The title of OpenAI’s technical report is also very meaningful: Video generation models as world simulators. (Video generation models as world simulators)
The last sentence of the technical report is also well written: We believe that the capabilities demonstrated by Sora today indicate that the continuous expansion of video models is a hopeful path to powerful simulators, capable of simulating the physical world, the digital world, and the objects, animals, and people living in these worlds.
In fact, as early as 2016, OpenAI explicitly stated that generative models are the most promising direction for computers to understand the world. They even quoted physicist Feynman’s words: What I cannot create, I do not understand. (What I cannot create, I do not understand)
2024-02-14
My mentor recommended that I read Peter Thiel’s Zero to One, truly a must-read for entrepreneurs. Peter Thiel is a Silicon Valley angel, a thinker in the investment world, and a founder of the PayPal Mafia.
Therefore, the author of “The Black Swan” commented on this book, saying that when a person with an adventurous spirit writes a book, it is a must-read. If the author is Peter Thiel, read it twice. But just to be safe, please read it three times, because “Zero to One” is definitely a classic.
The biggest takeaway from this book is that entrepreneurship and research are almost the same in many aspects.
All Profitable Companies Are Monopolies
The most interesting point in the book is that all successful businesses are different, or to say, all profitable companies are monopolies.
The monopolies discussed in the book are not those that rely on government resources to achieve monopoly, but those that innovate, making the products they supply to consumers unavailable from other businesses.
If there are multiple completely competitive companies in an industry, no matter how much value is created, the company’s profits will not be too much. For example, the American airline industry creates hundreds of billions of dollars in value every year, but airlines can only earn 37 cents from each passenger per flight. Google creates less value annually than the airline industry, but its profit margin is 21%, more than 100 times that of the airline industry.
Monopolists lie for self-protection, by positioning themselves as part of a larger market to fabricate non-existent competition. For example, Google does not position itself as a search engine company, but as an advertising company or a diversified technology company, the latter two markets being larger, with Google being just a minor player in the entire market.
And non-monopolists, in order to exaggerate their uniqueness, often define their market as the intersection of various smaller markets. For example, an English restaurant in Palo Alto, or the only company developing an email payment system (PayPal).
But describing the market too narrowly is a deadly temptation, it seems like you can naturally dominate it, but such a market may not exist at all, or it’s too small to support a company.
2024-02-07
(This article is reprinted from Jiazi Light Year’s official account, thanks to Jiazi Light Year for the interview)

Summarizing 2023, embarking on 2024.
Authors | Liu Yangnan Suhoi Zhao Jian
In the past week or two, many companies have been busily holding strategic meetings, clarifying their goals and plans for 2024.
After more than a year of AI’s rapid development, it’s time to make an annual summary of the busy 2023. After the strategic meetings and entering the Spring Festival holiday, most companies will truly stop their relentless pace and enter a brief and rare state of rest.
So, how to summarize the year 2023?
“Jiazi Light Year” invited more than 30 AI practitioners from fields such as foundational large models, AI Infra (AI infrastructure), multimodal, industry vertical scenarios, and academic research, and posed 5 questions:
What is your keyword for 2023?
When was the Magic Moment (the most impressive moment) you experienced in 2023?
Have you ever felt lost in the rounds of technological impacts in 2023? From confusion to enlightenment, what was the turning point?
Predict an important event that might happen in the AI industry in 2024?
What would you say to yourself a year ago? If you could ask yourself a year from now a question, what would it be?
Their confusion and anxiety, excitement and thrill, are a microcosm of the AI industry for the entire year; their exploration and perseverance, refresh and iteration, will be the prelude to the AI explosion in the next five years or even ten years.
Below are their shares (in alphabetical order of their names).