揭秘Google数据中心网络
导读:这是“走进 SIGCOMM 2013”系列的第二篇。Google 首次将其数据中心广域网 (WAN) 的设计和三年部署经验完整地公之于众,这篇论文可能被评为 Best Paper。为什么 Google 要用 Software Defined Networking (SDN)?如何把 SDN 渐进地部署到现有的数据中心?透过论文,我们能窥见 Google 全球数据中心网络的冰山一角。
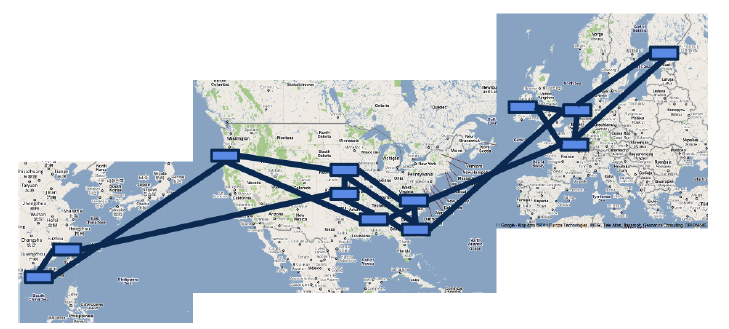
带宽的巨大浪费
众所周知,网络流量总有高峰和低谷,高峰流量可达平均流量的 23 倍。为了保证高峰期的带宽需求,只好预先购买大量的带宽和价格高昂的高端路由设备,而平均用量只有 30%40%。这大大提高了数据中心的成本。
这种浪费是必然的吗?Google 观察到,数据中心中的流量是有不同优先级的:
- 用户数据拷贝 到远程数据中心,以保证数据可用性和持久性。这个数据量最小,对延迟最敏感,优先级最高。
- 远程存储访问 进行 MapReduce 之类的分布式计算。
- 大规模数据同步 以同步多个数据中心之间的状态。这个流量最大,对延迟不敏感,优先级最低。
Google 发现高优先级流量仅占总流量的 10%~15%。只要能区分出高优先级和低优先级流量,保证高优先级流量以低延迟到达,让低优先级流量把空余流量挤满,数据中心的广域网连接(WAN link)就能达到接近 100% 的利用率。要做到这个,需要几方面的配合:
- 应用(Application)需要提前预估所需要的带宽。由于数据中心是 Google 自家的,各种服务所需的带宽都可以预估出来。
- 低优先级应用需要容忍高延迟和丢包,并根据可用带宽自适应发送速度。
- 需要一个中心控制系统来分配带宽。这是本文讨论的重点。
Why SDN?
计算机网络刚兴起时,都是插一根线连到交换机上,手工配置路由规则。在学校机房之类网络不复杂的情况下,时至如今也是这么做的。但是,只要增加一个新设备,就得钻进机房折腾半天;如果一个旧设备坏了,就会出现大面积的网络瘫痪。广域网络的维护者们很快就不能忍受了,于是就诞生了分布式、自组织的路由协议 BGP、ISIS、OSPF 等。
为什么设计成这样呢?有两方面原因。首先,七八十年代广域网络刚刚兴起时,网络交换设备很不稳定,三天两头挂掉,如果是个中心服务器分配资源,那么整个网络就会三天两头瘫痪。其次,Internet 是多家参与的,是 Stanford 愿意听 MIT 指挥,还是 MIT 愿意听 Stanford 指挥?
今天,在数据中心里,这两个问题都不复存在。首先,现在的网络交换设备和服务器足够稳定,而且有 Paxos 等成熟的分布式一致性协议可以保证“中心服务器”几乎不会挂掉。其次,数据中心的规模足够大,一个大型数据中心可以有 5000 台交换机(switch),20 万台服务器,与七八十年代整个 Internet 的规模已经相当了。数据中心是公司自家的,想怎么搞就怎么搞。
因此,Software Defined Networking (SDN) 应运而生。以 OpenFlow 为代表,SDN 把分散自主的路由控制集中起来,路由器按照 controller 指定的规则对 packet 进行匹配,并执行相应动作。这样,controller 就可以利用整个网络的拓扑信息和来自 application 的需求信息计算出一组接近全局最优的路由规则。这种 Centralized Traffic Engineering (TE) 有几个好处:
- 使用非最短路的包转发机制,将应用的优先级纳入资源分配的考虑中;
- 当连接或交换机出现故障,或者应用的需求发生变化时,动态地重新分配带宽,快速收敛;
- 在较高的层次上指定规则,例如(我随便编的)Gmail 的流量不经过天朝。
Design
Overview
交换机硬件是 Google 定制的,负责转发流量,不运行复杂的控制软件。
OpenFlow Controller (OFC) 根据网络控制应用的指令和交换机事件,维护网络状态。
Central TE Server 是整个网络逻辑上的中心控制器。
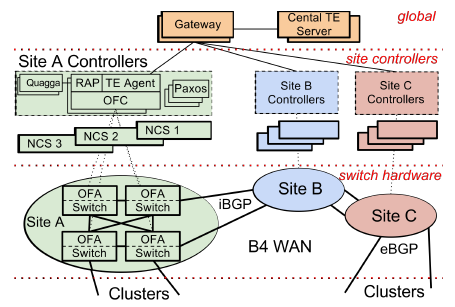 b4-2
b4-2第一条虚线上面是 Central TE (Traffic Engineering) Server。
一二两条虚线之间是每个数据中心(Site)的控制器,被称为 Network Control Server (NCS),其上运行着 OpenFlow Controller (OFC) 集群,使用 Paxos 协议选出一个 master,其他都是热备(hot standby)。
二三两条虚线之间是交换机(switch),运行着 OpenFlow Agent (OFA),接受 OFC 的指令并将 TE 规则写到硬件 flow-table 里。(这幅图里的细节读完本文就明白了)
Switch Design
Google 定制的 128 口交换机由 24 个 16 口 10Gbps 通用交换机芯片制成。(在本文中,“交换机”和“路由器”是通用的。需要说明工作在 MAC 层还是 IP 层时,会加定语 layer-2 或 layer-3)拓扑结构见下图。

蓝色的芯片是对外插线的,绿色的芯片充当背板(backplane)。如果发往蓝色芯片的 packet 目标 MAC 地址在同一块蓝色芯片上,就“内部解决”;如果不是,则发往背板,绿色芯片发到目标地址所对应的蓝色芯片。
交换机上运行着用户态进程 OFA (OpenFlow Agent),连接到远程的 OFC (OpenFlow Controller),接受 OpenFlow 命令,转发合适的 packet 和连接状态到 OFC。例如,BGP 协议的 packet 会被转发到 OFC 上,在 OFC 上运行 BGP 协议栈。
Routing
- RIB: Routing Information Base,路由所需要的网络拓扑、路由规则等
- Quagga: Google 采用的开源 BGP/ISIS 协议实现
- RAP: Routing Application Proxy,负责 OFA 与 OFC 之间的互联
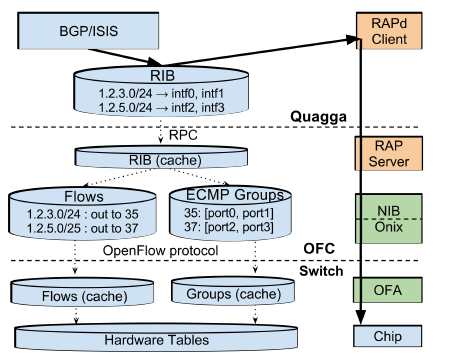 b4-4
b4-4
如上图所示,Quagga 路由协议栈中的 RIB 保存着路由规则,如发往某个子网的包要从某两个端口选一个出去。数据中心网络中一个 packet 一般会有多条路线可走,一方面提高冗余度,一方面充分利用带宽,常用的协议是 Equal Cost Multiple Path (ECMP),即如果有多条最短路,就从其中随机选一条走。
在 OFC 中,RIB 被分解为 Flows 和 Groups。要理解这个拆分的必要性,先要理解网络交换设备是怎样工作的。现代网络交换设备的核心是 match-action table。Match 部分就是 Content Addressable Memory (CAM),所有条目可以并行地匹配,匹配结果经过 Mux 选出优先级最高的一条;Action 则是对数据包进行的动作,比如修改包头、减少 TTL、送到哪个端口、丢弃数据包。
对路由规则来说,仅支持精确匹配的 CAM 是不够的,需要更高级的 TCAM,匹配规则支持 bit-mask,也就是被 mask 的位不论是0还是1都算匹配。例如需要匹配 192.168.0.0/24,前24位精确匹配,最后8位设为掩码即可。
在 OFC 中,Flows 对应着 Match 部分,匹配得出 Action 规则编号;Groups 对应着 Action 部分,采用交换机中现有的 ECMP Hash 支持,随机选择一个出口。
TE 算法
优化目标
系统管理员首先决定每个应用在每对数据中心之间所需的带宽和优先级,这就形成了一系列 {Source site, Dest site, Priority, Required bandwidth} 四元组(此处为了便于理解,对原论文进行了修改)。将这些四元组按照 {Source site, Dest site, Priority} 分组,把所需带宽加起来,就形成了一系列 **Flow Group (FG)**。每个 FG 由四元组 {Source site, Dest site, Priority, Bandwidth} 表征。
TE Optimization 的目标是 max-min fairness,就是在公平的前提下满足尽可能多的需求。由于未必可以满足所有需求,就要给“尽可能多”和“公平”下个定义。我们认为,客户的满意度是跟提供的带宽成正比的,也是跟优先级成反比的(优先级越高,就越不容易被满足);如果已经提供了所有要求的带宽,则满意度不再提高。在此假设基础上,引入 fair share 的概念,两个 Flow Group 如果 fair share 相同,就认为这两个客户的满意度相同,是公平的。
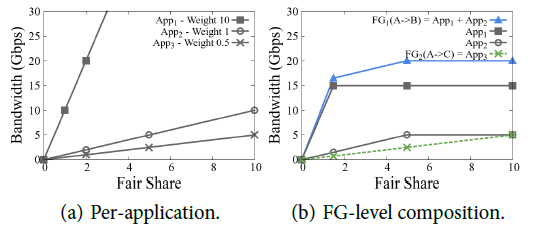
例子:App1 需要 A→B 的 15G 带宽,优先级为10,如下图方块所示;App2 需要 A→B 的 5G 带宽,优先级为1,如下图圆圈所示;App3 需要 A→C 的带宽多多益善(无上限),优先级为0.5,如下图 × 所示。我们首先把起点与终点相同的流合并成 Flow Group,得到蓝线所示的 FG1 = App1 + App2 和绿线所示的 App3。
TE Optimization 算法分下面三步:
- Tunnel Selection: 选择每个 FG 可能走的几条路线(tunnel)
- Tunnel Group Generation: 给 FG 分配带宽
- Tunnel Group Quantization: 将带宽离散化到硬件可以实现的粒度
选路
Tunnel Selection:利用 Yen 算法 [2],选出 k 条最短路,k 是一个常量。
例如下面的网络拓扑,取 k = 3:
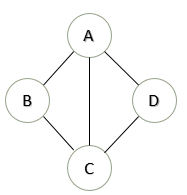
FG[1]: A → B
T[1][1] = A → B
T[1][2] = A → C → B
T[1][3] = A → D → C → B
FG[2]: A → CT[2][1] = A → C
T[2][2] = A → B → C
T[2][3] = A → D → C
在此为爱钻牛角尖的童鞋送上算法描述:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24# dist: adjacent matrix of node distances
# S: source node
# T: target node
# K: path num
# return: a matrix, each row is a path
def K_shortest_paths(dist, S, T, K):
A = []
A[0] = shortest_path(S, T)
for k in range(1, K):
distcopy = copy(dist)
for i in range(0, len(A[0])):
nodeA = A[k-1][i]
for j in range(0, k-1):
nodeB = A[j][i]
if (nodeA == nodeB):
distcopy[nodeA][nodeB] = inf
candidate[i] = A[0:i] + shortest_path(distcopy, nodeA, T)
A[k] = the path with minimum length for all candidate[i]
return A
# standard algorithm to find shortest path
# return: a list, shortest path from S to T
def shortest_path(dist, S, T):
pass
分配流量
Tunnel Group Generation: 根据流量需求和优先级分配流量。(论文中没有算法描述,我自己整理了一下。由于有些名词用中文写出来很别扭,就用英文了)
- Initialize each FG with their most preferred tunnels.
- Allocate bandwidth by giving equal fair share to each preferred tunnel.
- Freeze tunnels containing any bottlenecked link.
- If every tunnel is frozen, or every FG is fully satisfied, finish.
- Select the most preferred non-frozen tunnel for each non-satisfied FG, goto 2.
继续上面的例子。(文字解释见图片下方)
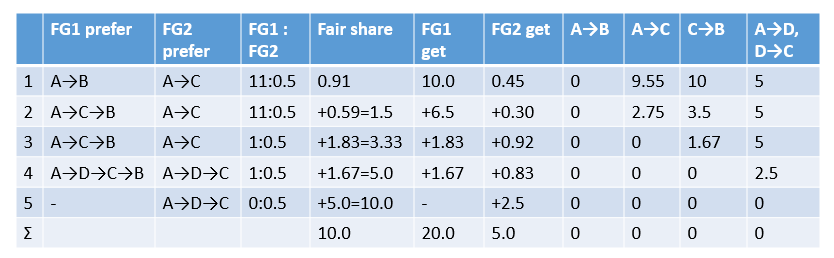
- 按照 FG1 和 FG2 最喜欢的 A→B 和 A→C 按 FG1:FG2 = (10+1):0.5 分配流量,想象流量一点点增长,直到 A→B 和 A→C 中的一条路堵死。FG1 所走的 A→B 先占满 10G 带宽,此时 fair share = 10/(10+1) = 0.91,FG2 分到 0.91*0.5 = 0.45G。
- 此时 A→B 已经不能走,FG1 最喜欢的未堵死路径是 A→C→B,FG2 最喜欢的路径 A→C 仍未堵死。在 fair share = 0.91 的基础上,首先按照 11:0.5 分配流量,直到 fair share = 1.5,此时 FG1 分到 (1.5-0.91)*11 = 6.5G,FG2 分到 (1.5-0.91)*0.5 = 0.30G。
- fair share = 1.5 是 fair share 折线图上的一个拐点,此后 FG1 中的 App1 已经满足(分到 15G),只给 App2 分配流量,因此“优先级”降为1。因此新的流量分配比例 FG1:FG2 = 1:0.5。路径不变 FG1 = A→C→B,FG2 = A→C,此时 A→C 首先堵死,fair share 增加了 (10G-0.45G-6.5G-0.3G) / (1+0.5) = 1.83,FG1 分到 1.83G,FG2 分到 0.92G。
- A→C 堵死后,FG1 最喜欢的路径是 A→D→C→B,FG2 最喜欢的路径是 A→D→C。按照 FG1:FG2 = 1:0.5 分配,fair share 增加到 5.0 时,A→D 和 D→C 的带宽还剩下 2.5G,C→B 刚好堵死。
- fair share = 5 是折线图上的另一个拐点,此时 FG1 中的 App2 也满足了,FG1 不再需要任何带宽。剩余的带宽全部分给 FG2,当所有路径都堵死时,fair share 增加了 5.0,也就是 FG2 分到 2.5G 带宽。
这个例子的分配结果是:
- FG1 分到 20G 带宽,其中 10G 走 A→B,8.33G 走 A→C→B,1.67G 走 A→D→C→B。
- FG2 分到 5G 带宽,其中 0.45G 走 A→C,1.22G 走 A→C→B,3.33G 走 A→D→C。
流量离散化
Tunnel Group Quantization: 由于硬件支持的流量控制不能无限精细,需要对上一步计算出的流量进行离散化。求最优解是个整数规划问题,很难快速求解。因此论文使用了贪心算法。
- Down quantize (round) each split.
- Add a remaining quanta to a non-frozen tunnel that makes the solution max-min fair (with minimum fair share).
- If there are still remaining quantas, goto 2.
继续上面的例子:
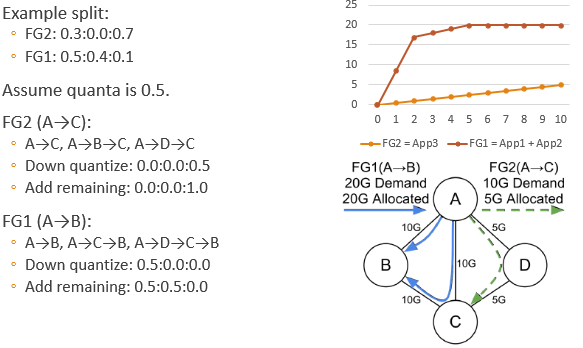
离散化会降低性能吗
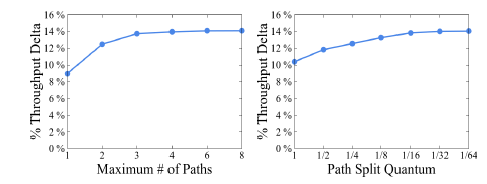
上图展示了离散化对性能的影响,这里的 Throughput Delta 是相对优化之前而言的,越大越好。可以看到,当流量分配粒度达到 1/16 后,再提高精细程度,就没有太多作用了。
在 Google 最终的实现中,tunnel 个数(前面的 _k_)设置为4,分配粒度为 1/4。至于为什么这么设置,you ask me, I ask who。
TE 实现
Tunneling
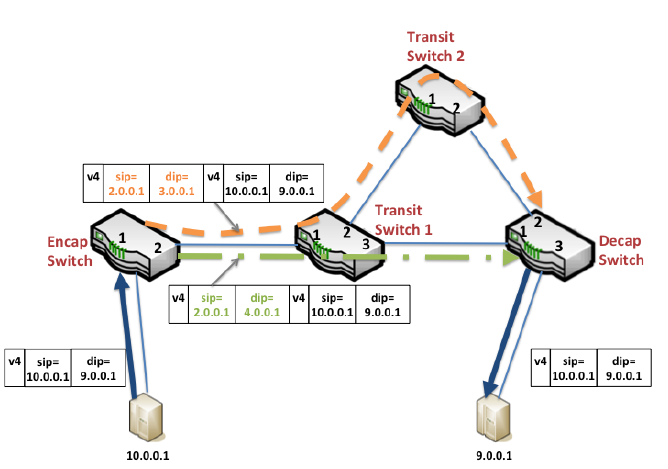
- Encap Switch 是连接终端机器的边界路由器,它们将 IP packet 封装起来,包上路由专用的 source ip 和 destination ip。
- Transit Switch 是中间传输路由器,它们只接受经过 Encap Switch 封装的 IP packet,并在数据中心之间进行路由。
- Decap Switch 是连接终端机器的边界路由器,其实跟 Encap Switch 是同一批机器。它们将被封装的 IP packet 剥掉一层皮,送给终端机器。
TE as Overlay
SDN “一步到位”的做法是设计一种统一的、集中式的服务,囊括路由和 Traffic Engineering。但这样的协议研发过程会很长。另外,万一出问题了,大家就都上不了 Google 了。
在这个问题上,Google 又发扬了“小步快走”的敏捷开发思想,把 TE 和传统路由两个系统并行运行,TE 的优先级高于传统路由,这样 SDN 就可以逐步部署到各个数据中心,让越来越多的流量从传统路由转移到 TE 系统。同时,如果 TE 系统出现问题,随时可以关闭 TE,回到传统路由。
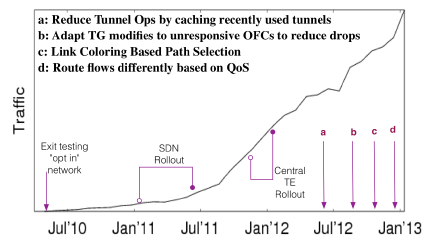
上图是 Google SDN 所承载的流量变化曲线。
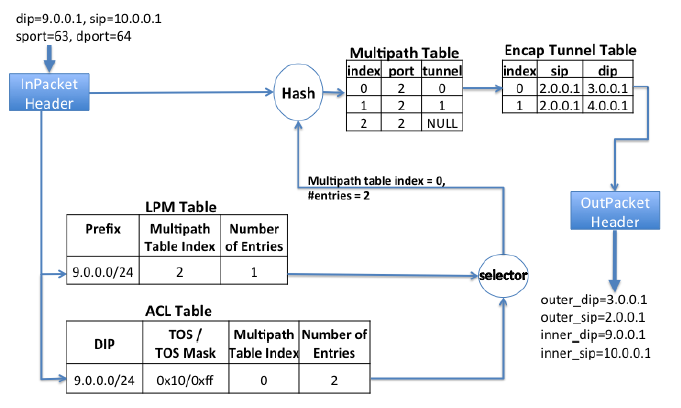
每个交换机都有两张路由表,LPM (Longest Prefix Match) Table 由基于最短路径的传统路由协议(BGP/ISIS)维护。ACL Table 是 TE 使用的路由表,优先级高于 LPM,也就是 LPM 和 ACL 都匹配出条目时,ACL 说的算。
上图的例子是 Encap Switch。匹配结果是一个 Multipath Table Index 和可选条数,也就是从 Index 开始的这么多条规则中根据 Hash 值选出一条规则。这条规则写明了出口(port)和路径(tunnel),再从路径表(Encap Tunnel Table)里查到要被封装到 IP packet 头部的 source IP 和 dest IP。对于 Transit Switch,就不需要路径表了。
操作依赖
一次 TE 变更可能涉及多个交换机的插入/删除规则操作,而这些操作不能以任意的顺序进行,否则就有可能出现丢包。因此有了两条规则:
- 在修改 Tunnel Group 和 Flow Group 之前,先在所有受影响的数据中心建立好 tunnel
- 在所有引用某 tunnel 的条目被删除之前,不能删除这个 tunnel
为了在有网络延迟和数据包乱序 (reordering) 的情况下保证依赖关系,中心 TE 服务器为每个事务(session)中的有序操作分配递增的序列号。OpenFlow Controller 维护当前最大的 session 序列号,拒绝任何比它小的 session 序列号。TE 服务器如果被 OFC 拒绝,将在超时后重试这个操作。
部署效果
统计
每分钟 13 次拓扑变化
去除维护造成的更新,每分钟 0.2 次拓扑变化
拓扑中的边添加/删除事件,一天 7 次(TE 算法运行在拓扑聚合后的视图上。两个数据中心之间可能有上百条 link,把它们聚合成一条容量巨大的 link。)
这方面的经验是:拓扑聚合明显降低了路径颠簸和系统负载
即使有拓扑聚合,每天也会发生好几次边的删除
WAN link 对端口颠簸(反复变化)很敏感,用中心化的动态管理收效较好
错误恢复
在数据中心,设备、线路损坏是常有的事,因此错误的影响范围和恢复速度很重要。

由上表可见,单条线路损坏只会中断连接 4 毫秒,因为受影响的两台交换机会立即更新 ECMP 表;一个 Encap Switch 损坏会使周边的交换机都更新 ECMP 表,比单条线路损坏多耗时一些。
但临近 Encap Switch 的 Transit Switch 挂掉就不好玩了,因为 Encap Switch 里有个封装路径表(Encap Tunnel Table),这个表是中心维护的,出现故障后邻近的 Encap Switch 要汇报给 OFC,OFC 汇报给全球中心的 TE Server(高延迟啊),TE Server 再按照操作依赖的顺序,逐个通知受影响的 Encap Switch 修改路径。由于这种操作很慢,需要 100ms,整个恢复事务需要 3300ms 才能完成。
OFC、TE Server 的故障都没有影响,首先因为它们使用了 Paxos 分布式一致性协议,其次即使全都挂掉了,也只是不能修改网络拓扑结构,不会影响已有的网络通信。由于前面提到的 TE as Overlay,关闭 TE 时,整个网络会回到基于最短路径的传统路由协议,因此也不会造成网络中断。
优化效果
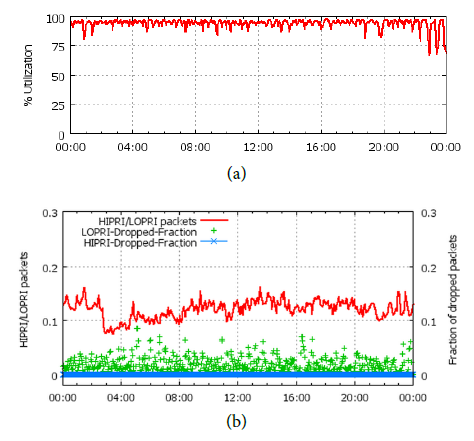
(a) 是平均带宽使用率,可以看到带宽使用率平均可达 95%。
(b) 是丢包率,其中占 10%~15% 比例(红线)的高优先级 packet 几乎没有丢包(蓝色),而低优先级 packet 有较多的丢包(绿色)。如果低优先级应用使用通常的 TCP 协议,在这么高的丢包率下很难高效工作。因此传输层协议也是要特殊设计的,不过论文并未透露。
一次事故
Google 的 SDN 系统曾经出现一次重大事故。过程是这样的:
- 一个新加入的交换机被不小心配置成了跟原有交换机一样的 ID。
- 两个 ID 相同的交换机分别发送 ISIS Link State Packet,收到的其他交换机感觉很奇怪,怎么这两份拓扑完全不一样呢?这两个 ID 相同的交换机都坚持自己的观察是正确的,导致网络中出现洪泛。
- TE 控制信令要从 OFC 发给 OFA,被网络阻塞了,造成了长达 400MB 的等待队列。
- ISIS Hello message(心跳包)也因为长队列而阻塞了,交换机们都认为周围的交换机挂掉了。不过 TE 流量仍然正常运行,因为它的优先级高于传统路由。
- 此时,由于网络拥塞,TE Server 无法建立新的 tunnel。雪上加霜的是,TE 依赖机制要求序列号较小的操作成功后才能进行下一个操作(见上文),建立新 tunnel 更是不可能了。因此,任何网络拓扑变化或设备故障都会导致受影响的网络仍在使用已经不能用的 tunnel。前面有统计数字,每分钟都会发生拓扑变化,因此这个问题是很严重的。
- 系统运维人员当时并不知道问题的根源,于是就重启了 OFC。不幸的是,这一重启,触发了 OFC 中未发现的一个 bug,在低优先级流量很大时不能自启动。
文中说,这次故障有几个经验/教训:
- OFC 与 OFA 之间通信的可扩展性和可靠性很重要。
- OFA 的硬件编程操作应该是异步并行的。
- 应该加入更多系统监控措施,以发现故障前期的警告。
- 当 TE 连接中断时,不会修改现有的路由表。这是一种 fail-safe 的措施,保证这次故障中已经建立的 tunnel 没有被破坏。
- TE Server 需要处理 OFC 无响应的情况。如果有的 OFC 挂掉了,与其禁止所有新建 tunnel 的操作,不如先让其中一部分运转起来。
结语
比起 SIGCOMM 2013 中其他数据中心方面的论文,本论文是唯一一篇经过广泛实践检验的。尽管文中的算法和思想都很朴素,但充分体现了工程领域中不得不做的 tradeoff。不得不说,Google 还是数据中心方面的老大,不鸣则已,一鸣惊人啊 :)
一些未来研究方向:
- 硬件编程的开销。OpenFlow 的规则顺序是很重要的,插入一条规则可能导致后面的规则都要移动,因此操作起来很慢。这是可靠性的主要瓶颈。
- OFC 与 OFA 间的通信瓶颈。OFC 和 OFA 间通信的可扩展性和可靠性不足。OpenFlow 最好能提供两个通信端口,分别支持高优先级操作和需要大带宽的数据传输。
我还做了一个 PPT(非官方),跟本文内容差不多:B4-Google-simcomm13
References:
- B4: Experience with a Globally-Deployed Software Defined WAN. to appear in SIGCOMM’13
- Yen, J. Y. Finding the K Shortest Loopless Paths in a Network. Management Science 17 (1971), 712-716.
- Koponen, T. Onix: a Distributed Control Platform for Large-scale Production Networks. In Proc. OSDI 2010, pp. 1-6.