大话同步/异步、阻塞/非阻塞
好多人搞不清这两组概念之间的区别。我们拿小明下载文件打个比方。
- 同步阻塞:小明一直盯着下载进度条,到 100% 的时候就完成。
- 同步非阻塞:小明提交下载任务后就去干别的,每过一段时间就去瞄一眼进度条,看到 100% 就完成。
- 异步阻塞:小明换了个有下载完成通知功能的软件,下载完成就“叮”一声。不过小明仍然一直等待“叮”的声音(看起来很傻,不是吗)
- 异步非阻塞:仍然是那个会“叮”一声的下载软件,小明提交下载任务后就去干别的,听到“叮”的一声就知道完成了。
也就是说,同步/异步是下载软件的通知方式,或者说 API 被调用者的通知方式。阻塞/非阻塞则是小明的等待方式,或者说 API 调用者的等待方式。
在不同的场景下,同步/异步、阻塞/非阻塞的四种组合都有应用。
同步阻塞
同步阻塞是最简单的方式,就像我们在 C 语言里调用一个函数并等待其返回。
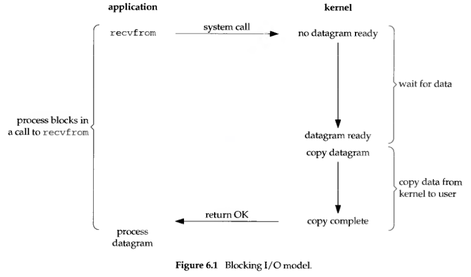
如 stat 系统调用获取文件元数据,只有同步阻塞一种模式。我在访问量很大的一个文件服务器(mirrors.ustc.edu.cn)上遇到过大量 nginx 进程处于 D(uninterruptible)状态的问题,就是因为 stat 系统调用不提供非阻塞 I/O(O_NONBLOCK)选项(nginx 在能用非阻塞 I/O 的地方都用了非阻塞)。文件的元数据被从磁盘中读入进来的时间里,这个 nginx worker 进程只能在内核态苦苦等待而无法做其他事。不提供 O_NONBLOCK 选项,对内核开发者来说这是省事了,但对用户来说就要付出性能的代价了。
同步非阻塞
同步非阻塞就是 “每隔一会儿瞄一眼进度条” 的轮询(polling)方式。
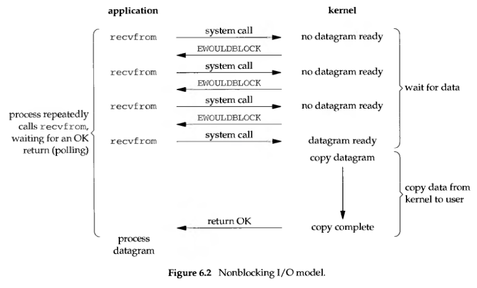
同步非阻塞方式相比同步阻塞方式:
- 优点是能够在等待任务完成的时间里干其他活了(包括提交其他任务,也就是 “后台” 可以有多个任务在同时执行)。
- 缺点是任务完成的响应延迟增大了,因为每过一段时间才去轮询一次,而任务可能在两次轮询之间的任意时间完成。
由于同步非阻塞方式需要不断轮询,而 “后台” 可能有多个任务在同时进行,人们就想到了循环查询多个任务的完成状态,只要有任何一个任务完成,就去处理它。这就是所谓的 “I/O 多路复用”。UNIX/Linux 下的 select、poll、epoll 就是干这个的(epoll 比 poll、select 效率高,做的事情是一样的)。Windows 下则有 WaitForMultipleObjects 和 IO Completion Ports API 与之对应(Windows API 的命名简直甩 POSIX API 几条街有木有!)
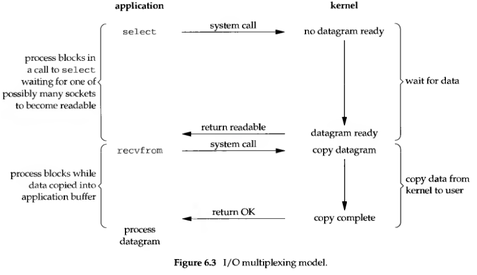 Linux I/O 多路复用
Linux I/O 多路复用
高并发的程序一般使用同步非阻塞方式而非多线程 + 同步阻塞方式。要理解这一点,首先要扯到并发和并行的区别。比如去某部门办事需要依次去几个窗口,办事大厅里的人数就是并发数,而窗口个数就是并行度。也就是说并发数是指同时进行的任务数(如同时服务的 HTTP 请求),而并行数是可以同时工作的物理资源数量(如 CPU 核数)。通过合理调度任务的不同阶段,并发数可以远远大于并行度,这就是区区几个 CPU 可以支持上万个用户并发请求的奥秘。在这种高并发的情况下,为每个任务(用户请求)创建一个进程或线程的开销非常大。而同步非阻塞方式可以把多个 I/O 请求丢到后台去,这就可以在一个进程里服务大量的并发 I/O 请求。
异步非阻塞
异步非阻塞,就是把一件事丢到 “后台” 去做,完成之后再通知。
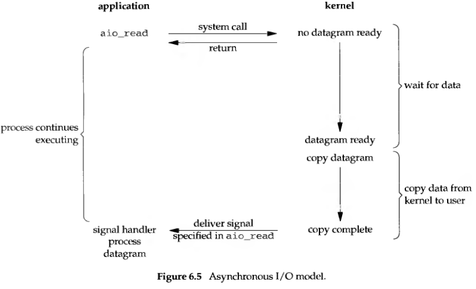
在 Linux 中,通知的方式是 “信号”。
- 如果这个进程正在用户态忙着做别的事(例如在计算两个矩阵的乘积),那就强行打断之,调用事先注册的信号处理函数,这个函数可以决定何时以及如何处理这个异步任务。由于信号处理函数是突然闯进来的,因此跟中断处理程序一样,有很多事情是不能做的,因此保险起见,一般是把事件 “登记” 一下放进队列,然后返回该进程原来在做的事。
- 如果这个进程正在内核态忙着做别的事,例如以同步阻塞方式读写磁盘,那就只好把这个通知挂起来了,等到内核态的事情忙完了,快要回到用户态的时候,再触发信号通知。
- 如果这个进程现在被挂起了,例如无事可做 sleep 了,那就把这个进程唤醒,下次有 CPU 空闲的时候,就会调度到这个进程,触发信号通知。
异步 API 说来轻巧,做来难,这主要是对 API 的实现者而言的。Linux 的异步 I/O(AIO)支持是 2.6.22 才引入的,还有很多系统调用不支持异步 I/O。Linux 的异步 I/O 最初是为数据库设计的,因此通过异步 I/O 的读写操作不会被缓存或缓冲,这就无法利用操作系统的缓存与缓冲机制。
Windows API 里的异步 I/O API(被称为 Overlapped I/O)则优雅得多,可以在 ReadFileEx、WriteFileEx 等 I/O API 上指定回调函数,当 I/O 操作完成时就会调用它。这相当于在 “信号” 的基础上提供了一层封装。除了指定回调函数,这些异步 I/O 请求还可以使用 “传统” 的同步阻塞方式(WaitForSingleObject)、多路复用的同步非阻塞方式(WaitForMultipleObjects)来等待。多个异步 I/O 请求也可以绑定到一个 I/O Completion Port 上一起等待。
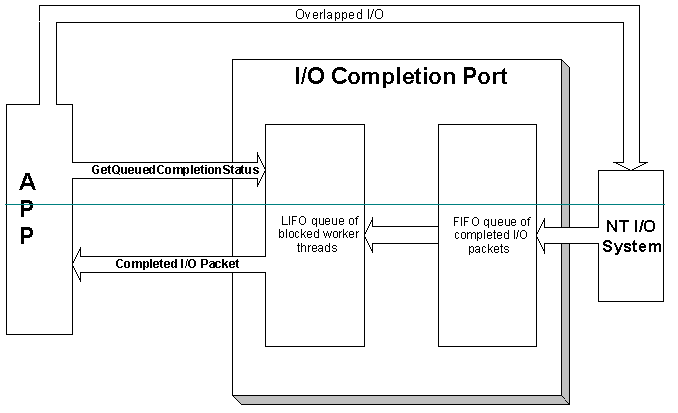 Windows 异步 I/O 原理
Windows 异步 I/O 原理
很多人把 Linux 的 O_NONBLOCK 认为是异步方式,但事实上这是前面讲的同步非阻塞方式。由于 Linux 的异步 I/O 难用,nginx 早期版本一直使用的是 O_NONBLOCK 和 epoll,从 0.8.11 开始支持异步 I/O,但默认使用的仍然是同步非阻塞方式。需要指出的是,虽然 Linux 上的 I/O API 略显粗糙,但每种编程框架都有封装好的异步 I/O 实现。操作系统少做事,把更多的自由留给用户,正是 UNIX 的设计哲学,也是 Linux 上编程框架百花齐放的一个原因。
异步阻塞
都有下载完成通知了,我还傻傻地盯着进度条干什么?这种看起来很傻的方式也是有用的。有时我们的 API 只提供异步通知方式,例如在 node.js 里,但业务逻辑需要的是做完一件事后做另一件事,例如数据库连接初始化后才能开始接受用户的 HTTP 请求。这样的业务逻辑就需要调用者是以阻塞方式来工作。
为了在异步环境里模拟 “顺序执行” 的效果,就需要把同步代码转换成异步形式,这称为 CPS(Continuation Passing Style)变换。BYVoid 大神的 continuation.js 库就是一个 CPS 变换的工具。用户只需用比较符合人类常理的同步方式书写代码,CPS 变换器会把它转换成层层嵌套的异步回调形式。
 CPS 变换后的异步代码示例(来源:continuation.js)
CPS 变换后的异步代码示例(来源:continuation.js)
 用户手写的同步代码示例(来源:continuation.js)
用户手写的同步代码示例(来源:continuation.js)
另外一种使用阻塞方式的理由是降低响应延迟。如果采用非阻塞方式,一个任务 A 被提交到后台,就开始做另一件事 B,但 B 还没做完,A 就完成了,这时要想让 A 的完成事件被尽快处理(比如 A 是个紧急事务),要么丢弃做到一半的 B,要么保存 B 的中间状态并切换回 A,任务的切换是需要时间的(不管是从磁盘载入到内存,还是从内存载入到高速缓存),这势必降低 A 的响应速度。因此,对实时系统或者延迟敏感的事务,有时采用阻塞方式比非阻塞方式更好。
最后补充一句,同步/异步的概念在不同语境下是不同的,本文说的是 API 或者 I/O。在其他语境里可能是别的意思,例如分布式系统里的同步表示是各节点按照时钟节拍同步,而异步是收到消息后立即执行。